
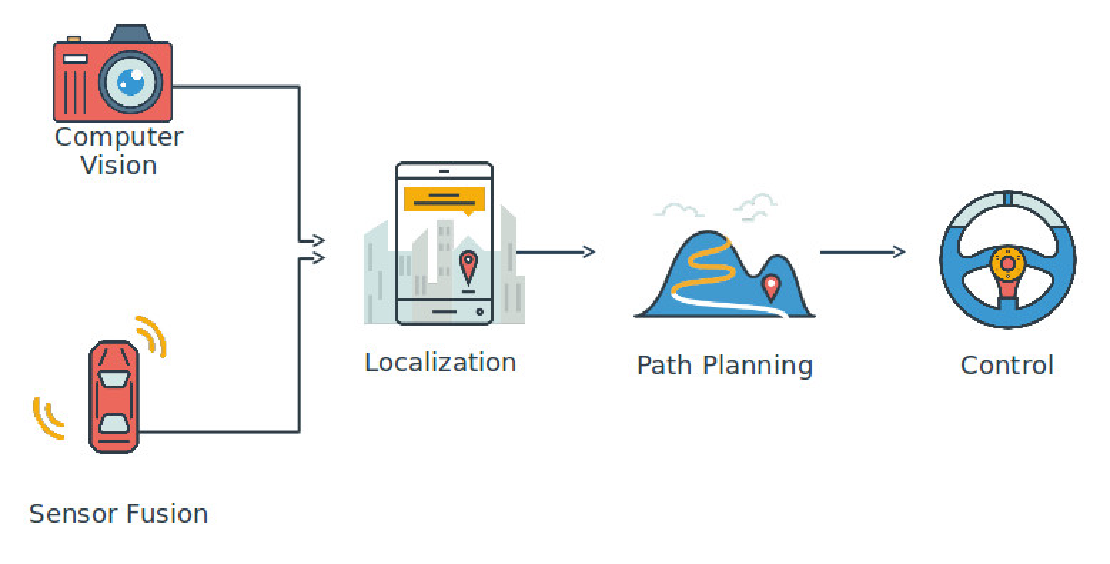
Computer Vision vs. Sensor Fusion: Who Wins the Self-Driving Car Race?
Tesla’s bold claim that “humans drive with eyes and a brain, so our cars will too” sparked one of the most polarizing debates in autonomous vehicle (AV) technology: Can vision-only systems truly compete with—or even outperform—multi-sensor fusion architectures?
At the core of this debate lies a fundamental design choice in how self-driving cars perceive and interpret their environment. Do you rely solely on high-resolution cameras feeding convolutional neural networks (CNNs), or do you incorporate data from LiDARs, radars, ultrasonic sensors, GPS, and IMUs into a probabilistic fusion framework?
Tesla Bet on Vision Alone—But Is That Enough?
This blog post dives deep into the technical foundations of both approaches—no marketing hype, just real-world system trade-offs.
The Vision-Only Pipeline: Simplicity at Scale
Computer vision-driven pipelines depend exclusively on camera feeds and vision algorithms to interpret the driving scene. In such systems, perception, localization, and planning are all derived from 2D (and inferred 3D) visual inputs. The typical sensor suite includes multiple cameras (e.g., wide-angle, fisheye, and long-range monocular) with overlapping fields of view.
Key Components and Algorithms:
- Convolutional Neural Networks (CNNs) for real-time object detection and semantic segmentation
- Monocular and stereo depth estimation for 3D understanding without active range sensors
- Structure-from-Motion (SfM) and Visual SLAM (Simultaneous Localization and Mapping) for ego-position tracking
- Visual-inertial odometry (VIO) when paired with an IMU for improved pose estimation
- Occupancy grid prediction and Bird’s-Eye View (BEV) transformation layers in modern neural nets
Advantages of Vision-Only:
- Lower hardware cost — cameras are significantly cheaper than LiDAR or high-resolution radar
- High spatial resolution — fine-grained details for understanding signs, lane markings, pedestrians
- Easier to scale in terms of manufacturing and deployment
- Lightweight compute pipelines when paired with dedicated vision accelerators (e.g., Tesla’s FSD Chip)
Challenges and Limitations:
- Poor low-light and adverse weather performance — vision degrades under fog, glare, snow, and nighttime
- Depth ambiguity — monocular cameras have no inherent mechanism to measure absolute distances
- Occlusion vulnerability — cannot “see through” or around obstacles like radar can
- Requires massive training datasets to learn long-tail edge cases and rare scenarios
- Longer convergence time in dynamic environments compared to systems with direct ranging
Sensor Fusion: Redundancy with Precision
Sensor fusion-based approaches rely on the integration of multiple complementary sensors to provide a robust, redundant understanding of the driving environment. The goal is not just perception, but confidence in perception—measured through probabilistic uncertainty modeling.
Typical Sensor Suite:
- LiDAR for high-fidelity 3D point clouds and environmental geometry
- Radar for accurate long-range object detection and relative velocity estimation
- Ultrasonic sensors for near-field object proximity detection
- IMU (Inertial Measurement Unit) and GNSS/GPS for precise localization and heading
- Cameras for classification, semantic understanding, and visual cues
Fusion Techniques Used:
- Kalman Filters and Extended Kalman Filters (EKF) for tracking and data fusion
- Bayesian occupancy grids and particle filters for probabilistic modeling of the environment
- Point cloud registration and scan-matching for SLAM and localization
- Multi-modal neural networks (early fusion, late fusion, or mid-level fusion) to learn sensor interactions
- Time-synchronized sensor pipelines using shared timestamps or common clocks (e.g., via PTP)
Strengths of Sensor Fusion:
- Redundant sensing enables failover — if one sensor fails or underperforms, others compensate
- Highly accurate localization — LiDAR + GPS + IMU enables centimeter-level positioning
- Weather and lighting resilience — radar works in fog, LiDAR handles low light
- Easier validation for safety standards due to decoupled, interpretable sensor models
- Real-time tracking of fast-moving or partially occluded objects with fused data
Trade-Offs and Challenges:
- Increased hardware complexity and cost — LiDAR units alone can be prohibitively expensive
- Synchronization challenges — multiple sensors require precise time alignment
- Data bandwidth and processing overhead — high-resolution LiDAR and camera feeds demand large compute
- Sensor calibration drift — performance can degrade over time without periodic recalibration
- Integration and testing effort scales non-linearly with each added sensor type
Compute Stack Comparison: Monolithic Learning vs Modular Architecture
The divergence in sensing strategies also impacts the compute architecture. Vision-only systems often favor end-to-end learning models that map raw pixels directly to driving actions or high-level waypoints. These are usually supported by tightly-coupled hardware and software co-designs.
Vision-Based Stack Characteristics:
- Uses centralized inference models — often transformer-based or multi-scale CNNs
- Optimized for throughput and low-latency inference on vision accelerators
- Relies heavily on self-supervised learning and temporal context (e.g., through recurrent layers or attention mechanisms)
- End-to-end learning reduces manual engineering but increases opacity
In contrast, sensor fusion stacks adopt a modular approach. Perception, localization, prediction, and planning are separated into distinct components that pass structured data between them.
Sensor Fusion Stack Characteristics:
- Modular by design — allows for independent validation of components
- Uses traditional control theory (e.g., PID, Kalman filters) alongside neural nets
- Compatible with middleware systems like ROS 2 and DDS for real-time communication
- Emphasizes redundancy and explainability — each decision can be traced to specific sensor data
Safety, Certification, and Regulatory Considerations
Safety is not just about perception quality—it’s about guaranteeing performance under all conditions, including edge cases and sensor degradation.
Vision-Only Stack Concerns:
- End-to-end models are harder to verify and interpret under functional safety standards like ISO 26262 or UL 4600
- Lack of redundancy makes failure modes harder to recover from
- Susceptible to adversarial attacks and perceptual illusions (e.g., adversarial stop signs)
Sensor Fusion Advantages in Safety:
- Modular architecture aligns better with safety assurance frameworks
- Redundancy enables graceful degradation of performance
- Easier to simulate and test sensor failure scenarios in isolation
- Can validate sensor outputs individually and in combination under SOTIF (Safety of the Intended Functionality)
The Scalability Factor: Mass Production vs Pilot Programs
Another axis of comparison is scalability. Vision-only systems are inherently more scalable due to simpler hardware, lower BOM (bill of materials) costs, and smaller form factors. They are well-suited for consumer-grade driver-assistance systems (ADAS) and incremental autonomy.
Sensor fusion stacks, with their higher hardware and compute requirements, are currently more viable in geo-fenced pilot programs (e.g., Waymo One) or tightly-controlled urban environments.
- Vision-only: Better fit for high-volume consumer vehicles with OTA updates and rapid iteration
- Sensor fusion: More reliable for fixed-route autonomous shuttles, robotaxis, or logistics fleets
So, Who Wins the Race?
There is no universal winner—only trade-offs shaped by technical, economic, and regulatory constraints. Here’s how the field splits:
Vision-only may excel in:
- Highway driving with structured lanes and predictable scenarios
- Scalable manufacturing and over-the-air (OTA) software improvements
- Cost-efficient autonomy at Level 2+ and Level 3 with human supervision fallback
Sensor fusion remains critical for:
- Complex urban environments with pedestrians, cyclists, and occlusions
- Full Level 4 and Level 5 autonomy with no human fallback
- Use cases where safety and fault tolerance take precedence over cost
Final Thought
The real question isn’t “who wins?” but “what are you optimizing for?” Is it affordability and mass-market deployment? Or is it unassailable safety and fail-safe operation in all weather and lighting conditions?
Vision systems are getting better, and the gap is closing fast—but for now, sensor fusion still holds the edge in operational safety and robustness. Future systems may blur the lines entirely, with vision-first architectures augmented by sparse LiDAR or next-gen radar.
Until then, the self-driving race remains open—driven as much by philosophy as by engineering.
Related Posts

What is SLAM? And Why It’s the Brain of Mobile Robots
In robotics, SLAM—Simultaneous Localization and Mapping—is regarded as one of the most fundamental and complex problems. At its core, SLAM addresses a deceptively simple question: “Where am I, and what does the world around me look like?”
Read more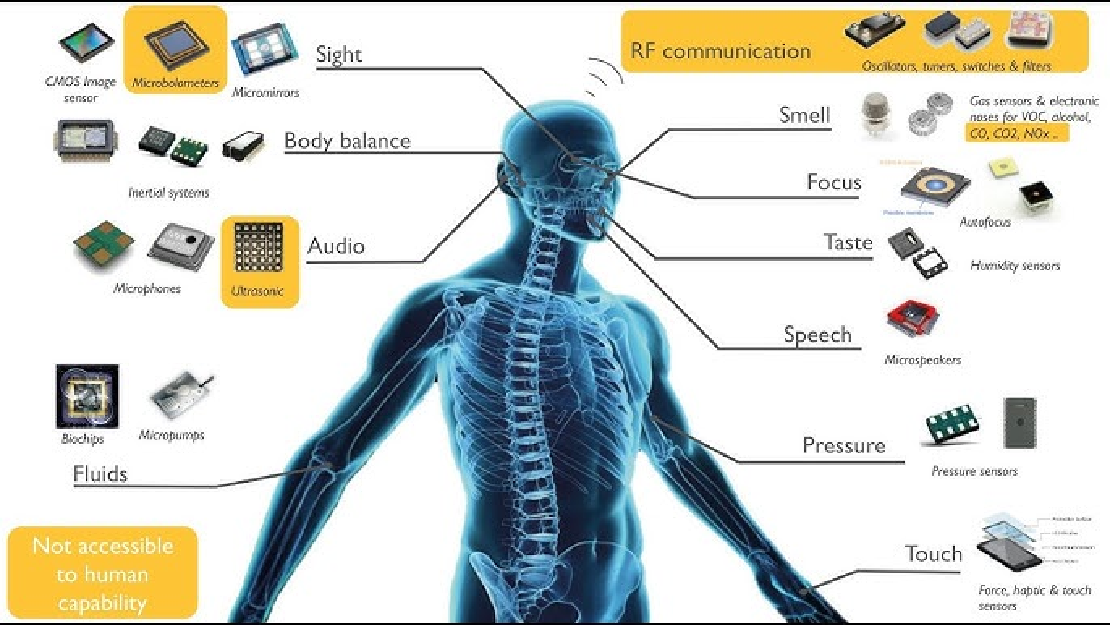
Sensors in Robotics: How Ultrasonic, LiDAR, and IMU Work
Sensors are to robots what eyes, ears, and skin are to humans—but with far fewer limits. While we rely on just five senses, robots can be equipped with many more, sensing distances, movement, vibrations, orientation, light intensity, and even chemical properties. These sensors form the bridge between the digital intelligence of a robot and the physical world it operates in.
Read more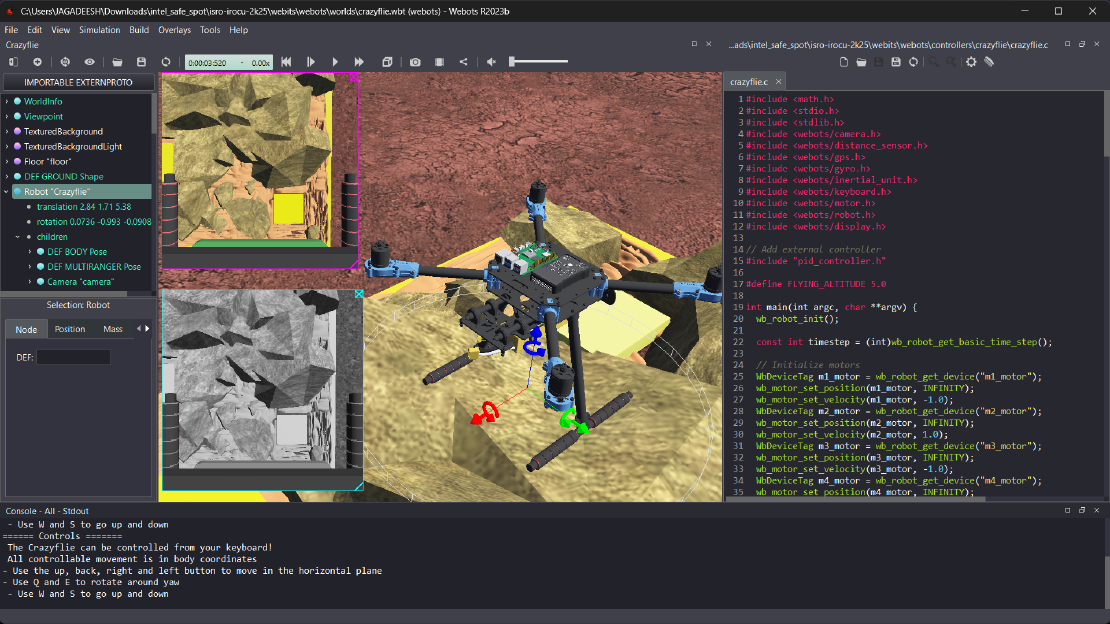
Debugging a Robot In Simulation Before You Burn Wires
Hardware does not come with an undo button. Once you power it on, mistakes—from reversed wiring to faulty code—can result in costly damage. Motors may overheat, printed circuit boards (PCBs) can be fried, and sensors may break. These issues turn exciting projects into frustrating repair sessions. The autonomous drone shown above, designed for GNSS-denied environments in webots as part of the ISRO Robotics Challenge, is a perfect example—where careful planning, testing, and hardware safety were critical at every step
Read more