

Why Everyone’s Talking About DeepSeek?
Over the last few weeks, one name has kept popping up across AI forums, Twitter feeds, and GitHub discussions: DeepSeek. Whether it’s about their models, benchmarks, or training philosophy, there’s been a noticeable shift in attention toward this new but fast-rising player in the open-source LLM space. But beyond the hype and headlines, what actually makes DeepSeek stand out in an increasingly crowded field?
Let’s break it down — technically.
What is DeepSeek?
At a glance, DeepSeek is a research group developing high-performance large language models with a strong emphasis on transparency and openness. The team, based in China, has already released a suite of general-purpose and domain-specific models, most notably under the names DeepSeek LLM and DeepSeek Coder.
These models aren’t just experimental—they’re capable enough to compete with some of the most well-known names in the LLM space. What’s drawn even more interest is that DeepSeek builds everything from scratch, doesn’t rely on LLaMA-style foundations, and releases its work with open weights and documentation.
General-purpose and Code-focused Models
The DeepSeek family is essentially split into two branches:
- DeepSeek LLM, designed for general language tasks like reasoning, summarization, translation, and dialogue.
- DeepSeek Coder, tailored specifically for code generation and software reasoning, capable of writing, completing, and debugging code across various programming languages.
The Coder line in particular has turned heads because of its competitive performance in real-world coding benchmarks. For tasks like function completion, problem solving, and even more subtle software engineering prompts, DeepSeek Coder has shown results on par with, or better than, popular models like StarCoder2, CodeLLaMA, and GPT-4-turbo in some scenarios.
Why People Are Paying Attention
A few technical choices and philosophical directions make DeepSeek especially interesting to both researchers and developers.
Training From Scratch
One of the most significant decisions DeepSeek made is to train their models from scratch. They don’t use Meta’s LLaMA weights, nor do they fine-tune on top of existing models. This means they have more control over the architecture, training data, tokenizer, and ultimately, the behavior of the model.
This also makes their models free from some of the licensing limitations that surround other open-weight models that build on proprietary foundations.
Massive Pretraining Dataset
DeepSeek’s models are trained on an impressively large and diverse dataset — reportedly around 2 trillion tokens. That places them among the larger pretraining efforts in the open-source LLM space.
The dataset includes a healthy mix of languages, code, web data, academic content, and mathematics. This broad exposure allows the models to generalize well across tasks and domains. Importantly, a significant portion of the data is in both English and Chinese, giving their models strong bilingual capabilities right out of the box.
Mixture of Experts (MoE): Smarter, Not Heavier
One of the more novel architectural choices in DeepSeek’s larger models is their use of Mixture of Experts (MoE). This is a technique where, instead of activating every part of the model for every input, only a selected group of “experts” (sub-models) are used depending on the input token.
For example, their 236-billion parameter model doesn’t use all 236B weights at once. Instead, only about 64 billion parameters are involved in any single forward pass. This keeps the model’s memory footprint and computational load lower than a dense model of the same size.
The benefits are pretty substantial — you can scale up the number of parameters (which helps capture a wider range of concepts and tasks), without paying the full cost of computing with all of them every time. It’s a step toward more efficient LLMs that don’t compromise too much on performance.
Strong Performance in English and Chinese
Another area where DeepSeek quietly but consistently stands out is its handling of both English and Chinese language tasks. Many LLMs today are English-centric, with support for other languages tacked on or unevenly represented in training data. DeepSeek took a different route, treating Chinese and English as equally important, and this balance shows in benchmarks.
Whether it’s reading comprehension, reasoning tasks, or translation, the models handle both languages with surprising fluency — making them especially relevant for bilingual or cross-lingual use cases.
Engineering and Infrastructure
While DeepSeek hasn’t released full technical papers detailing every training step, we do know quite a bit about their engineering stack. Their training infrastructure seems to combine many of the current best practices in large-scale model training:
- FlashAttention-2, which speeds up attention computation while saving memory
- FP16 and bfloat16 mixed precision, to balance precision and performance
- Distributed training techniques like ZeRO and expert parallelism, for efficient use of GPUs
It’s clear the team has optimized for both speed and stability at scale, which explains how they’ve managed to roll out models that perform well across a wide range of tasks without major quality issues.
Open Source with Real Substance
One of the biggest reasons DeepSeek is getting the attention it is today: they’re fully committed to open source. The models come with publicly available weights, usable licenses, tokenizer files, and in many cases, full training logs.
This is particularly important right now, as more major labs are shifting toward closed APIs and proprietary models. DeepSeek has positioned itself as one of the few teams at this scale that are still willing to share their work openly, enabling downstream research, fine-tuning, and deployment by the community.
This openness has already led to growing interest from academic labs, hobbyists, and even startups looking for strong base models they can build on.
Benchmarks and Real-World Performance
In testing, DeepSeek’s models have delivered strong results on both standard and specialized benchmarks:
- On HumanEval+, MBPP, and APPS, their Coder models show excellent Python and multi-language programming performance.
- On general reasoning and academic tasks like GSM8K, MMLU, and ARC, they’re often competitive with, or close to, the best models in their weight class.
- Their models are also being used more and more in community evaluation tasks like Arena, Chatbot Arena, and other crowd-ranking systems.
And it’s not just the top-line accuracy that impresses — many users have commented on how stable and predictable the models are across diverse input types, which is a strong signal of a solid training pipeline.
What’s Next for DeepSeek?
While we don’t have a full roadmap, the team has hinted at a few areas they’re exploring next:
- Expanding into multimodal models that can process images and text together
- Integrating tools and APIs to create agentic systems (LLMs that can use a calculator, browser, or code interpreter)
- Possibly scaling up even further, or making more advanced MoE variants public
There are also signs that DeepSeek is starting to build a stronger community presence, with model cards in English, discussion threads on HuggingFace, and public checkpoints optimized for inference and fine-tuning.
In Summary
DeepSeek has earned its recent buzz for good reason. It’s not just another LLM release — it’s a thoughtfully engineered, from-scratch family of models that manage to be both capable and open.
By combining large-scale bilingual training, efficient architectures like MoE, and a strong open-source stance, DeepSeek is carving out a unique space in the rapidly evolving LLM ecosystem.
It’s still early days, but if they continue in this direction, DeepSeek could play a major role in shaping the next generation of open AI tools — not just in China or in research circles, but globally.
Related Posts
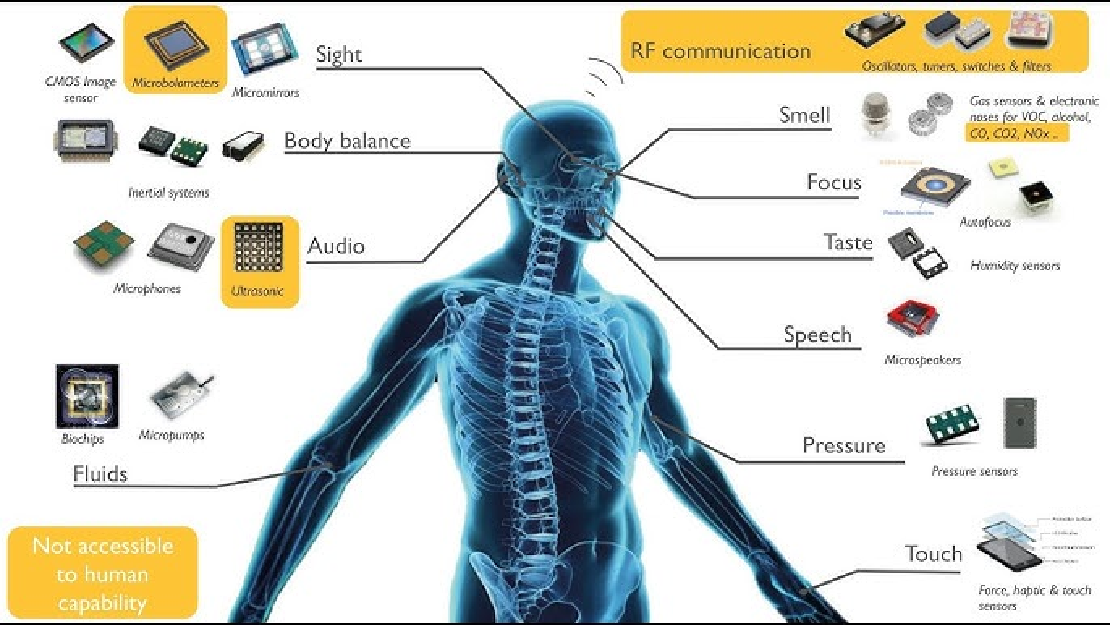
Sensors in Robotics: How Ultrasonic, LiDAR, and IMU Work
Sensors are to robots what eyes, ears, and skin are to humans—but with far fewer limits. While we rely on just five senses, robots can be equipped with many more, sensing distances, movement, vibrations, orientation, light intensity, and even chemical properties. These sensors form the bridge between the digital intelligence of a robot and the physical world it operates in.
Read more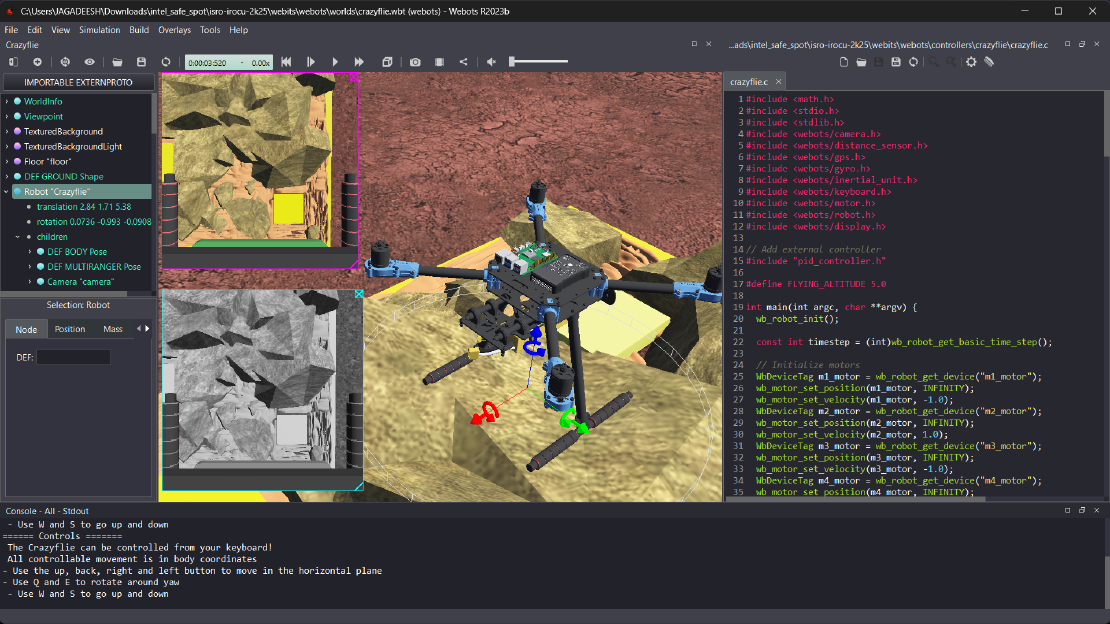
Debugging a Robot In Simulation Before You Burn Wires
Hardware does not come with an undo button. Once you power it on, mistakes—from reversed wiring to faulty code—can result in costly damage. Motors may overheat, printed circuit boards (PCBs) can be fried, and sensors may break. These issues turn exciting projects into frustrating repair sessions. The autonomous drone shown above, designed for GNSS-denied environments in webots as part of the ISRO Robotics Challenge, is a perfect example—where careful planning, testing, and hardware safety were critical at every step
Read more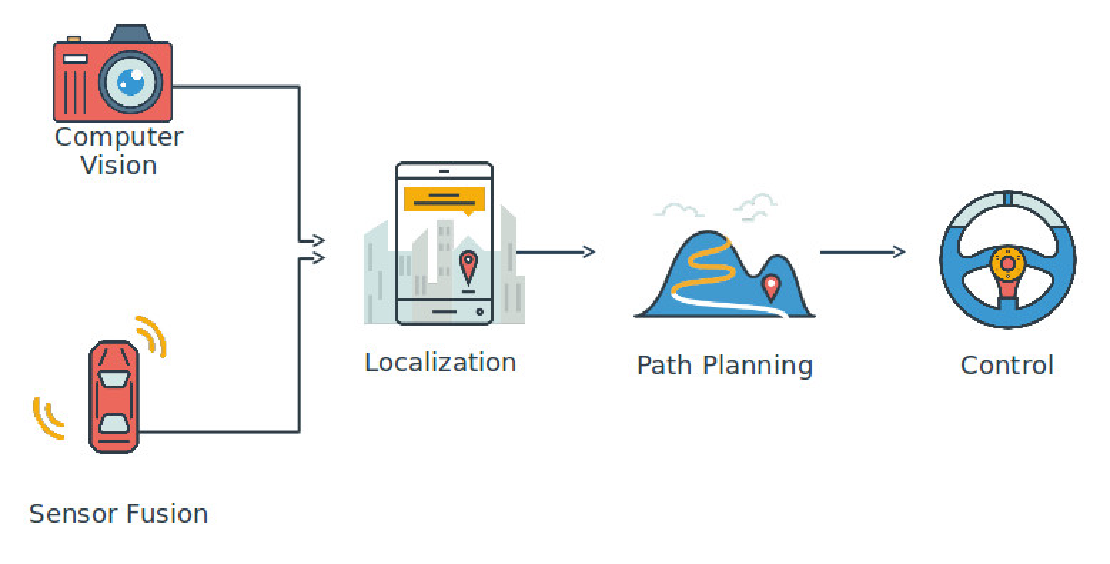
Computer Vision vs. Sensor Fusion: Who Wins the Self-Driving Car Race?
Tesla’s bold claim that “humans drive with eyes and a brain, so our cars will too” sparked one of the most polarizing debates in autonomous vehicle (AV) technology: Can vision-only systems truly compete with—or even outperform—multi-sensor fusion architectures?
Read more