
Hardware Scan-Line Triangle Rasterizer
Synthesisable fixed-function rasterizer in SystemVerilog. No floating-point anywhere in the RTL. Two builds: a scalar baseline (1 pixel/cycle) and a SIMD variant (OUT_W=8, 8 pixels/cycle as a masked warp). Both share the same arithmetic core, command front end, and verification infrastructure.
What It Does
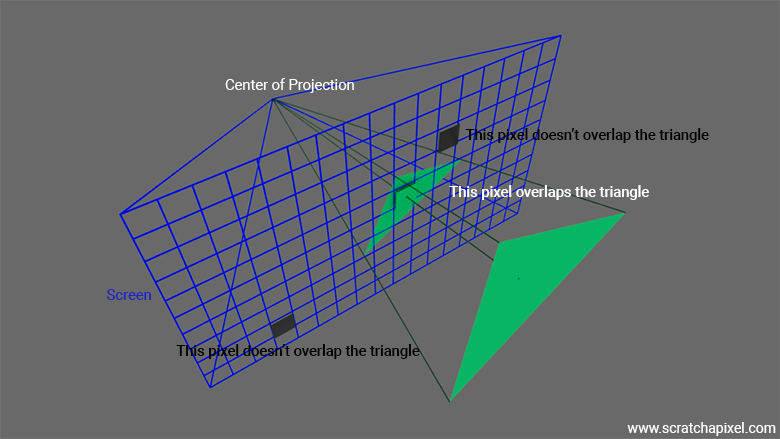
Takes a flat list of screen-space triangles with per-vertex RGB and renders them to a framebuffer. The pipeline is hardwired: edge setup, scan conversion, barycentric interpolation, Gouraud shading, framebuffer write. No programmable shader stages.
For 3D content a preprocessing step handles model transform, view transform, and perspective projection per frame and outputs projected 2D triangles. The hardware has no knowledge of 3D coordinates; all of that is resolved before the triangle list is handed off.
Architecture
Scalar datapath:
cmd_proc → edge_setup → rasterizer → frag_fifo → interp → pixel_shader → framebuffer
SIMD datapath:
cmd_proc → edge_setup → rasterizer(OUT_W=8) → warp_fifo → simd_interp → simd_pixel_shader → writeback_coalescer → framebuffer_mp
The SIMD rasterizer tests 8 horizontally adjacent pixels per cycle using a combinational generate loop over the row-start accumulators. Output is a masked warp: out_mask is 8 bits, one per lane, with lanes outside the triangle or past the row end already zeroed. framebuffer_mp has 8 independent write ports, all firing in the same clock edge.
Core Arithmetic
All arithmetic is signed fixed-point. Vertex coordinates are 16-bit signed. The SX macro sign-extends them to 32 bits before any multiply to prevent cross-product overflow on large triangles.
Edge equations. For edge $i \to j$:
$$E_{ij}(x,y) = A_{ij}\,x + B_{ij}\,y + C_{ij}$$A pixel is inside the triangle when all three evaluations are non-negative simultaneously. $A$, $B$, $C$ are computed once at triangle load. The scan walk then uses only additions: stepping right adds $A$, stepping down adds $B$. No multiplies in the inner loop.
Barycentric weights are the edge equation values themselves, forwarded directly from the coverage test at zero additional cost.
Gouraud shading blends per-vertex colors weighted by the barycentric coordinates, accumulated in 48-bit intermediates, divided by area2, and clamped to [0, 255].
Winding is normalized at load time by checking area2[31] and negating all six coefficients if negative. The SCAN state coverage test is always >= 0 with no branch per pixel.
Performance
| Scene | Triangles | Pixels | Scalar (cycles) | SIMD (cycles) | Speedup |
|---|---|---|---|---|---|
| Hello Triangle | 1 | 25,313 | 50,670 | 6,580 | 7.7x |
| Quads | 8 | 63,000 | 125,220 | 16,300 | 7.7x |
| Sunset | 20 | 72,752 | 146,736 | 19,426 | 7.6x |
Scalar throughput is 0.50 px/cyc across all three scenes. SIMD throughput is 3.85 to 3.87 px/cyc on the larger axis-aligned triangles, approaching the 4.0 px/cyc theoretical ceiling at 50% fill efficiency for warp size 8. The sunset’s small triangles (157 to 160 pixels each) pull the average to 3.75 px/cyc due to partial-warp overhead at row ends. Rasterizer backpressure is zero across all three SIMD runs.
Scenes
Hello triangle, quads, and sunset were the primary regression targets across both builds.

| Quads | Sunset |
|---|---|
 |  |
Photograph reconstruction using png2scene.py, which converts any image to a scene file by splitting it into an NxN cell grid and emitting two triangles per cell. At 256-cell resolution on a 256x256 framebuffer: 131,072 triangles.
| 6k triangles | 32k triangles | Final |
|---|---|---|
 |  |  |
3D animation target: a layer-by-layer Rubik’s cube solve. 3x3 cube, 54 stickers, 6 independent face colors, 3 independently rotating layers. The solve sequence is F R' F' R U R U' R' F R U R' U' R' F' R U' R'.

Verification
Constrained-random regression testbench (tb_gpu_top_cr.sv) with a Python golden model. 14 coverage buckets:
random_ccw random_cw degenerate_collin degenerate_samept
fully_offscreen partially_clipped thin_sliver full_screen
axis_aligned near_horizontal near_vertical screen_corner
single_row random_extra
Five independent checker blocks run cycle-by-cycle: cmd-proc protocol, rasterizer output bounds, FIFO push/pop integrity, pipeline drain (pixel conservation), and framebuffer write bounds.
Results against 98 triangles across all 14 buckets:
Triangles submitted : 98
Degenerate (dropped) : 14
Pixel count checks : 98 pass / 0 fail
CMD-proto errors : 0
Rast OOB pixel errors : 0
FIFO overflow errors : 0
FIFO underflow errors : 0
Pipeline drain errors : 0
FB OOB write errors : 0
FB write-during-clear : 0
SIMD: Two Failed Approaches Before the Final Design
Attempt 1: per-lane FIFOs with round-robin arbitration. The rasterizer stayed single-pixel and fed 4 per-lane FIFOs. A free-running round-robin counter popped one lane per cycle. Under uneven triangle coverage, lanes with more fragments backpressured the rasterizer. When the rasterizer stalled mid-row and resumed, pixel coordinates already in the FIFOs no longer matched the arbitration counter, producing out-of-order framebuffer writes. The images showed diagonal smearing and gradient tears.
| Hello Triangle (broken) | Quads (broken) |
|---|---|
 |  |
Attempt 2: warp scheduler FSM. Rasterizer stayed single-pixel and passed fragments to a scheduler that batched them into warps of size 8. Two problems: a one-cycle handshake gap when the scheduler transitioned from DISPATCH back to ACCUMULATE could drop the rast_done pulse on partial warps, losing the final warp per triangle. The writeback coalescer serialized warp lanes back to the framebuffer one pixel per cycle, taking 8 cycles to drain each warp and stalling the entire upstream during that window. Effective ceiling was 1 px per 8 cycles from the coalescer alone.
| Hello Triangle (warp FSM) | Quads (warp FSM) |
|---|---|
 |  |
Final design. The rasterizer was extended with OUT_W=8 to evaluate 8 lanes per cycle natively. A single warp FIFO (16 entries) sits between the rasterizer and interpolator. framebuffer_mp has 8 parallel write ports, all firing in one clock edge. No scheduler FSM, no serialized writeback, no arbitration counter.
| Hello Triangle (final) | Quads (final) | Sunset (final) |
|---|---|---|
 |  |  |