
ROSE: RISC-V Open-Source Env
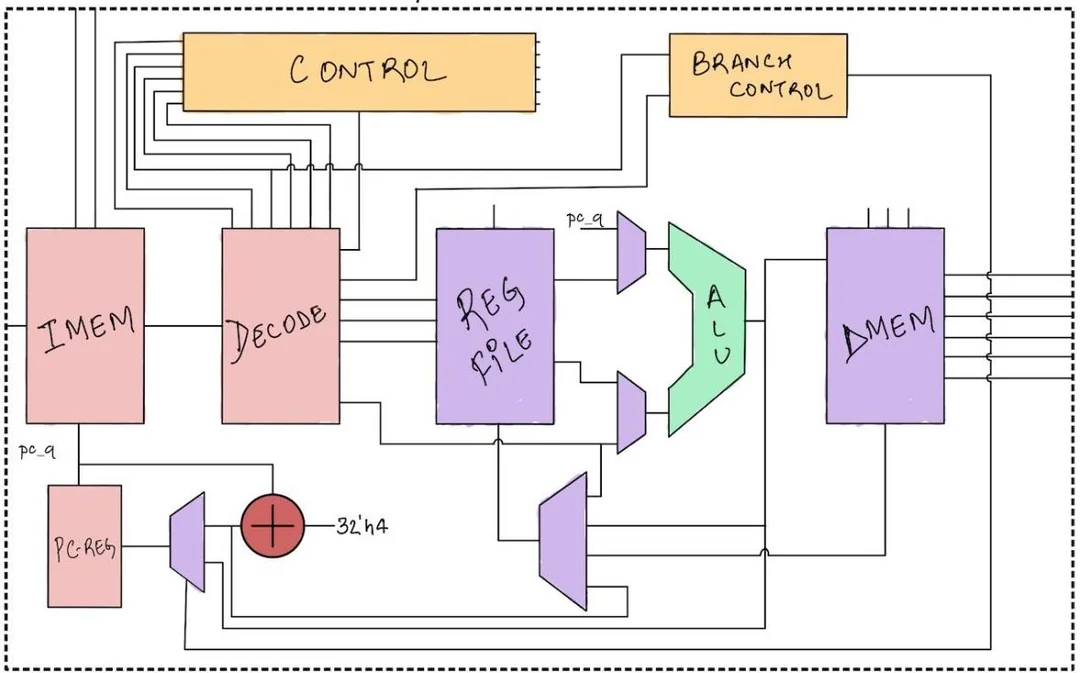
Dual Issue Superscalar RISC Processor
RISC-V & MIPS Microarchitectures — SC / MC / Pipeline / Dual-Issue
This umbrella project explores progressively complex processor microarchitectures, from single-cycle execution to a two-wide in-order superscalar design. All designs were verified using directed assembly programs and reference models.
Milestone Update (Mar-Apr 2026)
After the Electrothon competition, I continued this project with a stronger focus on verification, benchmarking, and OOO exploration.
- Added a QEMU + Spike cross-check flow for RV32I programs.
- Added support to compile and run arbitrary C files on RTL, then compare output windows against QEMU and Spike.
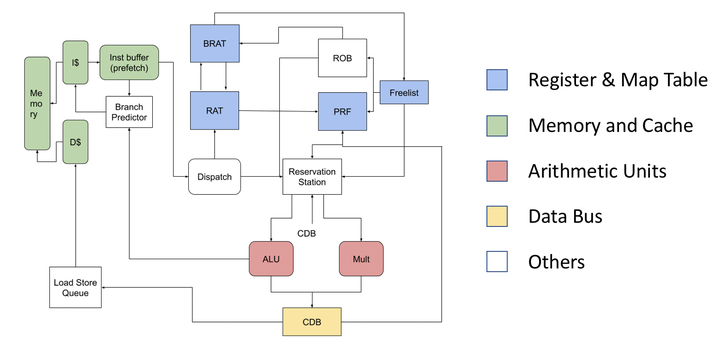
- Implemented a single-issue OOO RV32I core using a Tomasulo-style hybrid approach (tag wakeup/select + ROB in-order commit).
- Attempted a super-OOO variant; this turned out to be far more complex than I initially expected, so I am currently fixing it step by step.
- Added RV32IM support used for CoreMark bring-up and started working on CoreMark-focused tuning.
Common-Kernel Results Snapshot
| Variant | Common Kernels | Cycles | Instr | IPC | CPI |
|---|---|---|---|---|---|
| sc | 3 | 8972 | 8970 | 0.9998 | 1.0002 |
| mc | 3 | 39011 | 8970 | 0.2299 | 4.3491 |
| pipe | 3 | 12325 | 8970 | 0.7278 | 1.3740 |
| superscalar | 3 | 9395 | 8970 | 0.9548 | 1.0474 |
| ooo | 3 | 11548 | 8970 | 0.7768 | 1.2874 |
| super-ooo | 1 (partial) | 3183 | 2410 | 0.7571 | 1.3207 |
These are the shared common-kernel benchmark numbers from the current run. Super-OOO is still under active fixes, so only one common kernel is currently validated there.
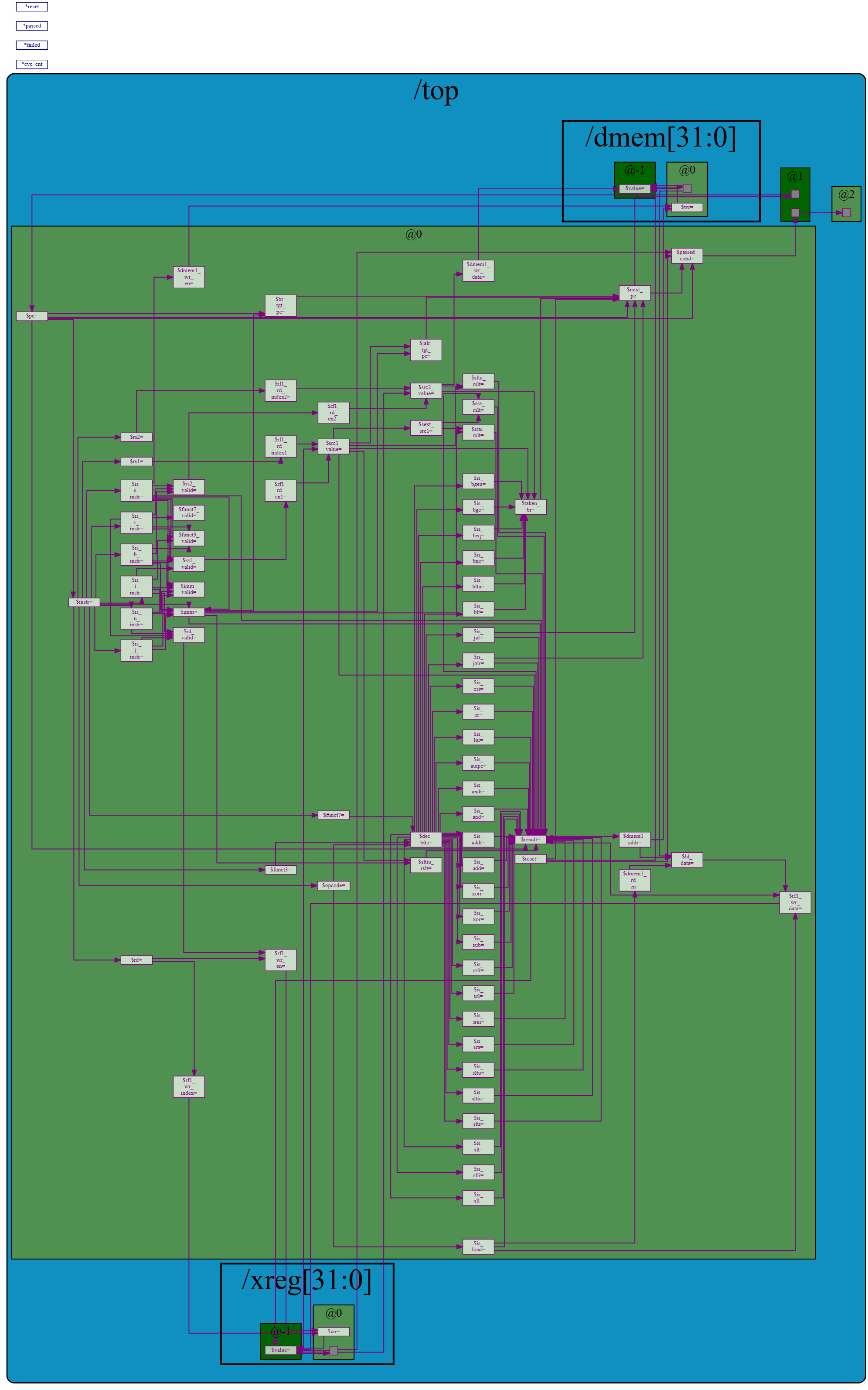
RV32I RISC-V Core (TL-Verilog, Single-Cycle)
Tools: Makerchip | TL-Verilog | Verilator
| Feature | Description |
|---|---|
| ISA | Full RV32I base (I, S, B, U, J, R formats) |
| Register File | 32 × 32-bit, dual-read / single-write |
| Invariance | ( x0 = 0 ) enforced |
| ALU | Arithmetic, logical, shift, compare |
| Verification | Directed program (sum 1–9) |
| Cycles | ~50 cycles for validation program |
Interactive visualization enabled via m4+cpu_viz() for cycle-accurate introspection.
RV32I RISC-V Core (Verilog, Single-Cycle)
Tools: Verilog | Icarus Verilog | ModelSim | Quartus Prime
| Feature | Description |
|---|---|
| Datapath | Modular ALU, control, imm-gen, PC logic |
| ISA Coverage | All 38 base RV32I instructions |
| Load/Store | LB, LBU, LH, LHU, LW, SB, SH, SW |
| Extensions | Correct sign/zero extension and RMW behavior |
| Verification | Self-checking ModelSim testbenches |
| Synthesis | Quartus Prime validated |
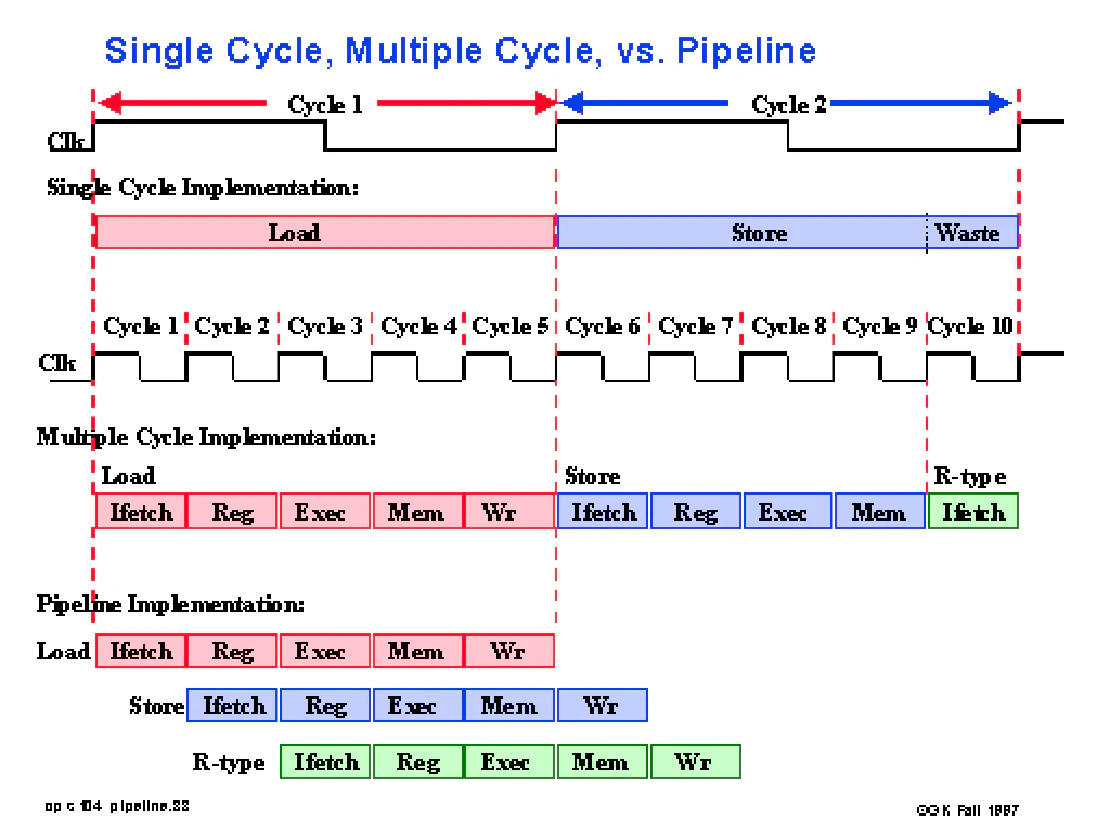
MIPS Microarchitectures — SC / MC / 5-Stage Pipeline
Tools: Verilog | Icarus Verilog | ModelSim | GTKWave
Three independent 32-bit MIPS implementations were developed and benchmarked.
Architectural Variants
| Design | Description | CPI |
|---|---|---|
| Single-Cycle | One instruction per cycle | 1.0 |
| Multi-Cycle | Instruction-dependent cycles | ~4.1 |
| 5-Stage Pipeline | IF–ID–EX–MEM–WB with forwarding | ~1.1–1.2 |
Multi-Cycle Instruction Latency
| Instruction Type | Cycles |
|---|---|
| R-type | 4 |
| I-type arithmetic | 4 |
| Load | 5 |
| Store | 4 |
| Branch | 3 |
| Jump | 3 |
RISCV Comparison
| Metric | SC | MC | Pipeline |
|---|---|---|---|
| Instructions | 13 | 13 | 13 |
| Cycles | 13 | 50 | 21 |
| CPI | 1.00 | 3.85 | 1.62 |
| IPC | 1.00 | 0.26 | 0.62 |
| Stall Cycles | 0 | 0 | 2 |
| Flush Cycles | 0 | 0 | 2 |
| Overhead Cycles | 0 | 37 | 8 |
MIPS Comparison
| Metric | SC | MC | Pipeline |
|---|---|---|---|
| Instructions | 18 | 18 | 18 |
| Cycles | 18 | 70 | ≈50 |
| CPI | 1.00 | 3.89 | ≈2.78 |
| IPC | 1.00 | 0.257 | ≈0.36 |
| Overhead Cycles | 0 | 52 | ≈32 |
Benchmark: Harris & Harris program (18 instructions) Correctly wrote ( 0x00000007 ) to memory addresses ( 0x50 ) and ( 0x54 ).
Dual-Issue 16-bit Superscalar RISC Processor (In-Order)
Tools: Verilog | Icarus Verilog | GTKWave
Architectural Overview
| Feature | Description |
|---|---|
| Issue Width | 2 instructions per cycle |
| Instruction Width | 16-bit |
| Fetch | 32-bit fetch (2×16-bit instructions) |
| Pipeline | IF–ID–EX–MEM–WB (dual lanes) |
| Register File | 4 read ports, 2 write ports |
| Memory | Multi-port ARAM (3-port) |
| Zero Register | ( r0 = 0 ) hardwired |
Hazard & Dependency Handling
- RAW detection
- WAW detection
- Inter-lane dependency suppression
- Load-use stall insertion
- Branch squashing
- Independent pipeline registers per lane
Lane-1 issue suppressed if hazard detected.
Verification Program
Directed program: Sum integers ( 1 \rightarrow 10 )
Expected: \[ \sum_{i=1}^{10} i = 55 \]
Final register: \[ r1 = 0x0037 \]
Correct inter-lane suppression observed for true dependencies.
Architectural Evolution Summary
| Stage | Focus |
|---|---|
| Single-Cycle | ISA correctness |
| Multi-Cycle | Resource reuse vs CPI tradeoff |
| 5-Stage Pipeline | Throughput vs hazard cost |
| Dual-Issue | Parallel issue, dependency management, structural scaling |
This umbrella project systematically explores performance scaling from scalar single-cycle execution to dual-issue in-order superscalar microarchitecture while maintaining architectural correctness and cycle-level validation.
Timeline Overview
Mar 2025 — First Exposure to RISC-V (TL-Verilog RV32I Core)
Work on processor design began around late March 2025 through an edX course by the Linux Foundation, which focused on building a RV32I CPU core using TL-Verilog.
During this phase:
Implemented a single-cycle RV32I processor in TL-Verilog using the Makerchip environment.
Supported the complete RV32I base ISA including all instruction formats (R, I, S, B, U, J).
Built the following datapath components:
- 32 × 32-bit register file (dual read, single write)
- ALU with arithmetic, logical, shift, and comparison operations
- Immediate generator
- Program counter logic
Enforced architectural invariants such as x0 = 0.
Verified functionality using a directed assembly test program (sum of integers 1–9).
Used Makerchip’s cycle-accurate visualization tools (
m4+cpu_viz) to inspect pipeline behavior.
This phase primarily served as an introduction to:
ISA structure
CPU datapath construction
instruction decoding
cycle-accurate execution tracing
The TL-Verilog implementation provided a visual and educational introduction to processor design before moving to conventional RTL.
Oct 2025 – Nov 2025 — Verilog RV32I Core and Microarchitecture Exploration
Later in October–November 2025, the processor was re-implemented entirely in Verilog RTL as part of a course project.
This time the design focused on a more conventional RTL microarchitecture rather than TL-Verilog abstractions.
Implementations Developed
Three variants of the same RV32I processor were implemented:
| Variant | Description |
|---|---|
| Single-Cycle | One instruction completes per clock cycle |
| Multi-Cycle | Instructions executed across multiple stages depending on type |
| 5-Stage Pipeline | IF–ID–EX–MEM–WB pipeline with forwarding |
Key features:
Modular datapath structure:
- ALU
- control unit
- register file
- immediate generator
- program counter logic
Full support for all 38 base RV32I instructions
Correct handling of:
- sign extension
- zero extension
- load/store alignment behavior
Verification using self-checking ModelSim testbenches
Simulation using Icarus Verilog and ModelSim
Synthesis validation in Quartus Prime
Performance Comparison
All three implementations were evaluated using the same benchmark program and data file, allowing direct comparison.
Metrics measured included:
- CPI
- IPC
- cycle counts
- pipeline stall cycles
- flush cycles
- architectural overhead
This created a controlled study of how architectural complexity affects performance.
Parallel Exploration — MIPS Microarchitectures
During the same period, a parallel implementation effort was undertaken using MIPS to explore architectural behavior across a different ISA.
Three MIPS processors were implemented:
| Design | Description |
|---|---|
| Single-Cycle | one instruction per clock |
| Multi-Cycle | instruction-dependent latency |
| 5-Stage Pipeline | IF–ID–EX–MEM–WB pipeline |
These designs were used to compare:
resource reuse
pipeline hazards
instruction latency
CPI differences across architectures
Benchmark used: Harris & Harris example program.
Oct–Nov 2025 — Early Superscalar Experiment (Parallel Work)
Alongside the scalar processors, an experimental superscalar processor was also implemented.
This processor was not RV32I-compatible, and instead used a small 16-bit custom RISC instruction set.
Because of the ISA mismatch, it was not directly comparable to the earlier processors.
Architecture
- Dual-issue in-order superscalar design
- Two instructions fetched per cycle (32-bit fetch)
- Two parallel pipelines
Pipeline stages:
IF → ID → EX → MEM → WB
Key hardware upgrades included:
- 4-read / 2-write port register file
- dual-port / multi-port memory architecture
- inter-lane dependency detection
- RAW hazard detection
- WAW hazard detection
- load-use stall insertion
- branch squashing
- independent pipeline registers per lane
If a dependency was detected:
lane-1 issue suppressed
processor falls back to single-issue mode
Supported instruction types were limited:
basic R-type
basic I-type
This processor was mainly an early attempt to understand superscalar issue logic rather than a full ISA implementation.
This dual-issue superscalar implementation was not built completely from scratch. I spent time going through a few open-source designs, mainly biRISC-V and SoomRV, along with a few others, to understand how real designs handle issue logic, dependency checking, and pipeline coordination. Many of these are written in C++-based frameworks or Bluespec, so the focus was more on understanding the ideas rather than the exact implementation.
Based on that, I implemented a simplified dual-issue in-order superscalar processor in Verilog on my own. To keep things manageable, this version uses a reduced 16-bit instruction set, so the effort could stay focused on core mechanisms like inter-lane hazard handling, register file scaling, and dual-lane pipeline behavior rather than full ISA complexity.
Dec 2025 — Reference Model Verification Using QEMU
During the December 2025 vacation period, the verification infrastructure was improved.
The emulator QEMU was used as a reference model.
The following states were compared between the RTL simulation and QEMU execution:
- program counter
- register dumps
- memory states
This significantly improved confidence in the correctness of the RV32I implementations.
The superscalar prototype could not be validated using QEMU because its ISA differed from RV32I.
Mar 2026 — Electrothon Hackathon (HackS’US / C-DAC Thiruvananthapuram)
In March 2026, the project entered a new phase during a 42-hour national hackathon organized by:
- HackS’US RSET IEDC
- C-DAC Thiruvananthapuram
Competition: Electrothon
The challenge required designing a RV32I processor implementation of any architecture.
This work expanded the earlier processor designs into a more modular and structured framework.
Architectures Implemented
Four RV32I cores were developed:
| Architecture | Description |
|---|---|
| Single-Cycle | baseline architecture |
| Multi-Cycle | resource-reusing execution |
| 5-Stage Pipeline | classic IF–ID–EX–MEM–WB pipeline |
| Dual-Issue Superscalar | two-wide in-order design |
The superscalar design was re-implemented using RV32I ISA compatibility, unlike the earlier experimental processor.
Due to time constraints, the superscalar design used:
- 4-read / 2-write register file
- single-port memory
- hazard suppression logic
- supports all instructions
Superscalar Features
- two-wide fetch
- parallel pipelines
- inter-lane RAW/WAW hazard detection
- load-use stalls
- branch squashing
- dual-issue scheduling
- fallback to single-issue mode when dependencies occur
Performance Evaluation
Custom hardware performance counters were added to measure:
CPI
IPC
execution latency
cycle counts
All cores were tested using the same benchmark programs.
FPGA Demonstration
The processors were synthesized and demonstrated on a Spartan-7 FPGA, with comparisons of:
- LUT utilization
- architectural complexity
- performance scaling
Competition Result
The project won:
1st Place — National Level
42-Hour Hackathon
Mar-Apr 2026 - Post-Competition Development
After the competition, work continued directly on this codebase as a practical extension of the hackathon prototypes.
Major progress in this phase:
- Brought up a repeatable QEMU + Spike reference flow for RV32I verification.
- Added generic C-program execution flow so arbitrary C files can be compiled, simulated on RTL, and cross-checked with QEMU/Spike memory dumps.
- Implemented a single-issue out-of-order RV32I core and connected it to the existing benchmarking flow.
- Attempted a super-OOO version; this design proved much more complex than expected in real implementation, and it is currently being stabilized.
- Added RV32IM support needed for CoreMark-oriented work and started ongoing CoreMark optimization and validation.
- Have benchmarked all variants and explored tradeoffs; and optimised pipelined variant.
Alongside implementation work, I also studied superscalar and benchmark literature, including:
“Design of a 32-bit Dual Pipeline Superscalar RISC-V Processor on FPGA” by Kuruvilla Varghese.
The paper included additional architectural features such as:
- branch prediction
- performance evaluation using CoreMark
- performance evaluation using Dhrystone
This provided further context for future improvements.
ISA Compliance Testing — RISC-V ACT
To verify ISA correctness, the RISC-V ACT (Architecture Compliance Tests framework) suite was integrated.
The tests verified whether the processors fully complied with the official RV32I ISA specification.
Most cores passed the compliance tests successfully.
A few tests were skipped because Icarus Verilog simulation became extremely slow for large memory jumps and long execution traces.
Current Status (Apr 2026)
Current work is focused on consolidating post-competition progress into a stable and reproducible research workflow.
Active status:
- QEMU + Spike cross-check flow is working for RV32I verification.
- Arbitrary C files can be run end-to-end through RTL and compared against software references.
- SC, MC, PIPE, and Superscalar variants are benchmarked in a common framework.
- Single-issue OOO is implemented and under continued tuning.
- Super-OOO is under active fixes; it was far more complex in practice than I initially imagined.
- RV32IM support for CoreMark work is integrated, and CoreMark optimization is also done.
Near-term direction:
stabilize single-issue OOO first
fix super-OOO correctness path by path
complete CoreMark-focused tuning and reporting
extend benchmark-driven verification across all variants
Future experiments involve:
superscalar scheduling improvements
out-of-order variants and other RISC-V extensions
This project has grown into a setup for exploring different microarchitectures, starting from basic RV32I designs and moving toward superscalar and out-of-order variants, with a consistent focus on correctness and verification.
The super-OOO version has been more difficult than expected. I am working through it step by step, stabilizing it incrementally on top of the single-issue OOO design.