RV32I(M) Processor Variants
This project implements six different microarchitectural variants of a RISC-V RV32I processor, ranging from a simple single-cycle design to a complex dual-issue out-of-order superscalar machine. All variants pass the official RISC-V compliance tests (37 rv32ui + 8 rv32um tests) and share a common verification infrastructure.
Tools and Versions
Python: 3.10.12
Spike: 1.1.1-dev
QEMU: 6.2.0
Iverilog: Icarus Verilog version 11.0
Verilator: 5.044 (2026-01-01)
GCC: riscv64-unknown-elf-gcc 10.2.0
GCC: riscv32-unknown-elf-gcc 10.2.0
All variants use these tools for compilation, simulation, and verification. Spike serves as the golden reference for instruction retirement counts and output signatures. QEMU provides an alternative cross-check path. Iverilog handles fast functional simulation while Verilator offers cycle-accurate performance analysis. Benchmark numbers in this document are from GCC 10.2.0 with -O0 as used by benchmark/run_benchmarks.py. Changing GCC version or optimization level changes the generated assembly. Branch and loop behavior is especially sensitive to this, so IPC/CPI results move accordingly.
Architectural Overview
RV32I-SC (Single Cycle)
The simplest implementation. Every instruction completes in exactly one clock cycle.
┌─────────────────────────────────────────────────────────┐
│ Single Cycle Path │
└─────────────────────────────────────────────────────────┘
┌────────┐ ┌────────┐ ┌─────┐ ┌──────┐ ┌──────────┐
│ PC │──>│ IMEM │──>│ DEC │──>│ ALU │──>│ DMEM │
│ REG │ │ │ │ RF │ │ BCMP │ │ │
└────────┘ └────────┘ └─────┘ └──────┘ └──────────┘
^ │ │
└────────────────────────────────────┴───────────┘
(combinational)
Key Features:
- All operations execute combinationally within one cycle
- No pipeline registers
- Clock period must accommodate worst-case path (typically a load instruction)
- Simple control logic
- CPI = 1.0 exactly
Components:
- ALU (alu.v)
- ALU control (alu_ctrl.v)
- Branch comparator (branch_compare.v)
- Control decoder (control.v)
- Register file (registers.v) - 2 read, 1 write port
- PC register (pc_reg.v)
- Immediate generator (imm_gen.v)
- CSR registers (csr_reg.v)
The single-cycle design trades clock frequency for simplicity. There is no hazard detection, no forwarding, and no speculation. It directly implements the ISA semantics.
RV32I-MC (Multi-Cycle)
A finite state machine based design where each instruction takes multiple cycles to complete, but only one instruction executes at a time.
State Machine (6 states): IF -> ID -> EX -> MEM -> WB -> HALT
Cycle 1: IF (fetch from IMEM, load IR)
Cycle 2: ID (decode, read RF)
Cycle 3: EX (ALU operation, branch resolve)
Cycle 4: MEM (DMEM access if needed)
Cycle 5: WB (write RF if needed)
Then next instruction starts at IF.
Instruction Latencies:
- R-type/I-type: 4 cycles (IF, ID, EX, WB)
- Branches: 3 cycles (IF, ID, EX)
- Loads: 5 cycles (IF, ID, EX, MEM, WB)
- Stores: 4 cycles (IF, ID, EX, MEM)
Key Features:
- FSM control with explicit state encoding
- Instruction register (IR) holds opcode across cycles
- ALU reused for address calculation and PC update
- Lower hardware cost than single-cycle (shared ALU, smaller muxes)
- CPI ranges from 3 to 5 depending on instruction mix
Components: Same basic blocks as SC, enhanced with:
- State machine controller
- Instruction register
- ALU output register
- Memory data register
The multi-cycle approach reduces the critical path length (faster clock possible) at the cost of throughput. No instruction-level parallelism.
RV32I-PIPE (5-Stage Pipeline)
Classic RISC pipeline with forwarding and hazard detection.
IF -> ID -> EX -> MEM -> WB
┌────┐ ┌────┐ ┌────┐ ┌─────┐ ┌────┐
│ PC │->│ RF │->│ALU │->│DMEM │->│ RF │
│IMEM│ │DEC │ │BCMP│ │ │ │ WB │
└────┘ └────┘ └────┘ └─────┘ └────┘
| | | | |
[IF/ID][ID/EX][EX/MEM][MEM/WB]
Forwarding paths:
EX/MEM -> EX (bypass fresh ALU result)
MEM/WB -> EX (bypass load data or older result)
Hazards:
Load-use -> stall IF, ID (1 cycle bubble)
Branch -> flush ID, EX (2 cycle penalty)
Pipeline Registers:
- IF/ID: PC, instruction
- ID/EX: operands, immediates, control signals, register addresses
- EX/MEM: ALU result, memory data, control, destination register
- MEM/WB: result, control, destination register
Key Features:
- Forwarding unit - 2-bit encoding for each operand
- Hazard detection - load-use stalls, control flush
- Branch resolution in EX stage (2 cycle penalty for taken branches)
- Ideal CPI approaches 1.0 with minimal hazards
- Actual CPI ~1.33 on mixed workloads due to dependencies and branches
Components: All SC components plus:
- Forwarding logic
- Hazard detection unit
- Pipeline register stages
The pipeline overlaps execution of multiple instructions but remains in-order. Data hazards are resolved by forwarding when possible, stalling when necessary (load-use). Control hazards cause pipeline flushes.
RV32I-SUPERSCALAR (2-Way In-Order)
Dual-issue superscalar processor that can fetch, decode, execute, and commit two instructions per cycle while maintaining in-order semantics.
Dual Fetch (PC, PC+4):
┌──────────────────────────────────────────────────────┐
│ Slot 0 Slot 1 │
│ ┌────┐ ┌────┐ ┌────┐ ┌────┐ ┌────┐ ┌────┐ │
│ │IF/0│->│ID/0│->│EX/0│ │IF/1│->│ID/1│->│EX/1│ │
│ └────┘ └────┘ └────┘ └────┘ └────┘ └────┘ │
│ | | | | | | │
│ [IF/ID] [ID/EX] [EX/MEM] [IF/ID] [ID/EX] [EX/MEM]│
│ | | | | | | │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │MEM/0│ │ WB/0│ │MEM/1│ │ WB/1│ │
│ └─────┘ └─────┘ └─────┘ └─────┘ │
└──────────────────────────────────────────────────────┘
Register File: 4 read ports, 2 write ports
(ra1/rd1, ra2/rd2 for slot 0; ra3/rd3, ra4/rd4 for slot 1)
(wa0/wd0 for slot 0 WB; wa1/wd1 for slot 1 WB)
Inter-slot Forwarding:
Slot 1 can use Slot 0 EX result in same cycle (3-bit encoding)
Dispatch Restrictions:
- If slot 0 is a load and slot 1 reads its destination, squash slot 1
- If slot 0 is a branch/jump, squash slot 1 (wrong path)
- If slot 0 is a store and slot 1 is a load, squash slot 1 (memory ordering)
- Both slots stall together on load-use hazard
Key Features:
- Dual control units for parallel decode
- Enhanced forwarding with 3-bit encoding for slot 1
- Hazard unit with inter-slot dependency detection
- Squash mechanism for fine-grained slot 1 cancellation
- PC update: +8 (dual dispatch), +4 (single dispatch), or branch target
- Maximum IPC = 2.0, practical IPC ~1.3 on balanced workloads
Components: Dual versions of pipeline components:
- Dual control, dual immediate generators
- 4R2W register file
- Dual ALUs, dual memory ports
- Enhanced forwarding and hazard logic
The superscalar design extracts instruction-level parallelism by issuing two independent instructions per cycle. Conservative dependency checks and memory ordering constraints limit throughput on tightly coupled code.
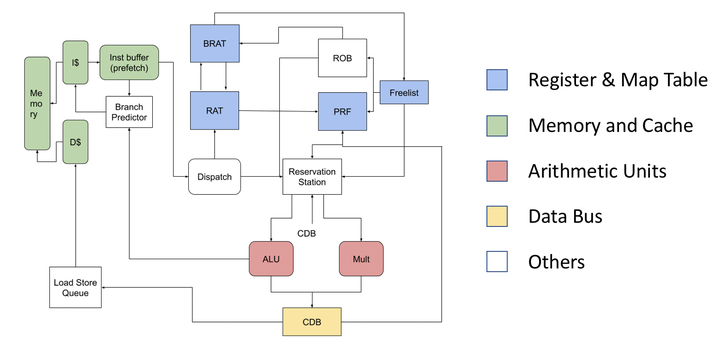
RV32I-OOO (Single-Issue Out-of-Order)
Tomasulo-style dynamic scheduler with register renaming, speculative execution, and in-order retirement.
Frontend (In-Order):
┌────┐ ┌────────┐
│ IF │-->│ ID │
└────┘ └────────┘
|
v
┌──────────┐ ┌─────────────┐
│ RAT │<---->│ Register │
│ (Rename) │ │ File (32x) │
└──────────┘ └─────────────┘
|
v
┌──────────┐ ┌─────────────┐
│ ROB │ │ Issue Queue │
│ (16 ent) │<---->│ (16 ent) │
└──────────┘ └─────────────┘
| |
| v
| ┌──────────┐
| │ Execute │
| │ (OOO) │
| └──────────┘
| |
v v
┌──────────┐ ┌───────────┐
│ Commit │<-----│ CDB │
│(In-Order)│ │(Broadcast)│
└──────────┘ └───────────┘
RAT (Register Alias Table):
Maps each architectural register to ROB tag if result pending
ROB (Reorder Buffer):
Holds speculative results, commits in-order
IQ (Issue Queue):
Holds instructions waiting for operands, issues oldest-ready
CDB (Common Data Bus):
Broadcasts results to wake up dependent instructions
Execution Flow:
- Fetch/Decode: Instruction enters pipeline
- Rename: Allocate ROB entry, read RAT for source tags, update RAT for destination
- Dispatch: Insert into IQ with operand values or tags
- Issue: Select oldest instruction with all operands ready
- Execute: Compute result, write to ROB
- Broadcast: CDB updates IQ (wakeup) and ROB
- Commit: Retire oldest ready instruction, write register file, clear RAT alias
Key Features:
- ROB depth 16
- Issue queue depth 16
- Register alias table (rat.v)
- Store-load hazard checking via ROB query
- Branch misprediction flushes ROB, IQ, RAT
- Single-issue per cycle (dispatch, execute, commit all 1-wide)
- Dynamic scheduling eliminates false dependencies (WAR, WAW)
Components:
- ROB: circular buffer, in-order commit
- IQ: age-based priority, dual CDB wakeup
- RAT: 32-entry mapping table
- LSQ: load-store queue for memory disambiguation (lsq.v, partially used)
The out-of-order design exploits instruction-level parallelism by executing instructions as soon as operands are available, regardless of program order. Register renaming removes false dependencies. Precise exceptions are maintained through in-order commit from the ROB.
RV32I-SUPER-OOO (2-Way Superscalar Out-of-Order)
The most aggressive design: dual-fetch, dual-dispatch, dual-issue, dual-execute, dual-commit with full out-of-order execution.
Frontend (2-wide):
┌─────┐ ┌─────┐
│IF/0 │ │IF/1 │ (fetch PC, PC+4 each cycle)
└─────┘ └─────┘
| |
┌─────┐ ┌─────┐
│ID/0 │ │ID/1 │ (dual decode)
└─────┘ └─────┘
| |
v v
┌─────────────────┐ ┌──────────────┐
│ RAT (2-write) │<---->│ Register File│
│ (commit 2-wide) │ │ (4R2W) │
└─────────────────┘ └──────────────┘
| |
v v
┌─────────────────┐ ┌──────────────┐
│ ROB (dual alloc)│ │ IQ (2-issue) │
│ (16 ent) │<---->│ (16 ent) │
└─────────────────┘ └──────────────┘
| | | |
| | v v
| | ┌────────────┐
| | │ EX/0 EX/1 │
| | │ (symmetric)│
| | └────────────┘
| | | |
v v v v
┌─────────────────┐ ┌──────────────┐
│ Commit (2-wide) │<-----│ CDB (quad) │
│ (mem in-order) │ │ (wb0,wb1, │
└─────────────────┘ │ cm0,cm1) │
└──────────────┘
Quad CDB:
CDB0: EX0 writeback
CDB1: EX1 writeback
CDB2: ROB commit 0 (load data)
CDB3: ROB commit 1 (load data)
Dispatch Rules:
- Can dispatch 0, 1, or 2 instructions per cycle
- Slot 0 always eligible if ROB/IQ not full
- Slot 1 restrictions:
- Cannot dispatch if slot 0 is control flow (branch/JAL/JALR)
- Cannot dispatch if slot 1 itself is control flow
- Intra-pair dependency (slot 1 reads slot 0 destination) handled via bypass
Key Features:
- Dual-width ROB (rob.v) - allocate/commit up to 2 per cycle
- Dual-issue queue (issue_queue_2w.v) - select 2 oldest-ready
- Dual-width RAT (rat.v) - 2 write ports, quad read ports
- Quad CDB for maximum wakeup bandwidth
- Symmetric execution units (both can do any operation)
- Maximum IPC = 2.0
- Configurable: can degrade to single-dispatch or in-order issue
Components:
- Dual-width ROB, IQ, RAT
- 4R2W register file
- Dual execution pipelines
- Quad CDB broadcast network
The super-OOO variant combines superscalar width with dynamic scheduling. It can sustain two instructions per cycle when parallelism is available. The quad CDB ensures that wakeup bandwidth matches issue width. Memory operations still commit in-order to preserve correctness.
Comparison Table
| Feature | SC | MC | PIPE | SUPERSCALAR | OOO | SUPER-OOO |
|---|---|---|---|---|---|---|
| Pipeline Stages | 1 | 5 (FSM) | 5 | 5 (dual) | Variable | Variable |
| Max IPC | 1.0 | 0.25 | 1.0 | 2.0 | 1.0 | 2.0 |
| Fetch Width | 1 | 1 | 1 | 2 | 1 | 2 |
| Issue Width | 1 | 1 | 1 | 2 | 1 (OOO) | 2 (OOO) |
| Commit Width | 1 | 1 | 1 | 2 | 1 | 2 |
| Instruction Window | 1 | 1 | 5 | 10 | 16 (ROB) | 16 (ROB) |
| Register Renaming | No | No | No | No | Yes (RAT) | Yes (RAT) |
| Out-of-Order Exec | No | No | No | No | Yes | Yes |
| Forwarding | No | No | Yes | Yes | Via CDB | Via CDB |
| Hazard Detection | No | No | Yes | Yes | Dynamic | Dynamic |
| ROB Depth | - | - | - | - | 16 | 16 |
| Issue Queue Depth | - | - | - | - | 16 | 16 |
| Control Complexity | Low | Low | Medium | High | Very High | Extreme |
Benchmark Kernels
The project includes microbenchmarks to stress different architectural features. All kernels are written in C and compiled with -march=rv32i -O0 for consistency.
Common Kernels (all variants):
alu_chain: Long dependency chain of ALU operations stressing forwarding and OOO schedulingmem_stream: Streaming memory accesses with minimal dependencies, tests memory bandwidthilp_mix: Two independent arithmetic chains exposing instruction-level parallelism
Pipe vs Superscalar (p2s_*):
p2s_clean_ilp2: Two perfectly independent lanes, ideal for dual-issuep2s_lane_dep_alu: Inter-lane ALU dependencies forcing squashes in superscalarp2s_lane_dep_mem: Inter-lane memory dependencies stressing dispatch logic
Pipe vs OOO (p2o_*):
p2o_low_ilp_chain: Tight dependency chain where OOO provides little benefitp2o_mid_ilp_dual: Moderate parallelism with two interleaved chainsp2o_high_ilp4: Four independent chains maximally exploiting OOO windowp2o_mem_overlap: Memory operations with intervening independent work, tests OOO memory overlap
Benchmark Results
How to Read Missing Entries
-means that kernel is not in the target set for that variant inbenchmark/run_benchmarks.py.invalid(x)means simulation producedxcycles but failed Spike signature validation, so it is excluded from speedup aggregation.NAin pairwise tables means there are no common validated kernels for that comparison.
Kernel Cycle Matrix
Per-kernel cycle counts across variants.
| Kernel | Instr | sc | mc | pipe | superscalar | ooo | super-ooo |
|---|---|---|---|---|---|---|---|
| alu_chain | 2,410 | 2411 | 10,333 | 3,026 | 2,412 | 3,322 | 3,183 |
| mem_stream | 1,811 | 1811 | 7,902 | 2,591 | 2,074 | 2,630 | invalid(231) |
| ilp_mix | 4,749 | 4750 | 20,776 | 6,708 | 4,909 | 5,596 | invalid(264) |
| p2s_clean_ilp2 | 8,817 | - | - | 11,160 | 8,815 | - | invalid(152) |
| p2s_lane_dep_alu | 11,633 | - | - | 15,834 | 11,633 | - | invalid(181) |
| p2s_lane_dep_mem | 8,242 | - | - | invalid(11,454) | invalid(9,049) | - | invalid(565) |
| p2o_low_ilp_chain | 10,475 | - | - | 13,203 | - | 14,747 | 14,319 |
| p2o_mid_ilp_dual | 12,925 | - | - | 17,128 | - | 16,496 | invalid(163) |
| p2o_high_ilp4 | 13,173 | - | - | 17,436 | - | 20,900 | invalid(158) |
| p2o_mem_overlap | 10,225 | - | - | 14,525 | - | 17,604 | invalid(1,068) |
Pairwise Tradeoffs
Geomean speedup comparing targeted kernel sets (only validated results):
| Comparison | Common Kernels | Geomean Speedup | Mean Speedup | IPC Delta | CPI Delta |
|---|---|---|---|---|---|
| pipe vs superscalar | 2 | 1.3127x | 1.3136x | +0.2377 | -0.3135 |
| pipe vs ooo | 4 | 0.8944x | 0.8982x | -0.0756 | +0.1656 |
| pipe vs super-ooo | 1 | 0.9221x | 0.9221x | -0.0618 | +0.1065 |
| superscalar vs super-ooo | 0 | NA | NA | NA | NA |
| ooo vs super-ooo | 1 | 1.0299x | 1.0299x | +0.0212 | -0.0409 |
Observed Results and Reasons:
The superscalar variant shows a 1.31x geomean speedup over pipe on the two validated p2s_* kernels (p2s_clean_ilp2, p2s_lane_dep_alu). Those kernels are built with two independent chains, so the 2-wide in-order front end gets real lane utilization.
The single-issue OOO variant is slower than pipe on this benchmark set (0.8944x geomean in pipe vs ooo). In this implementation, rename/dispatch/commit are still 1-wide and retirement is ordered through ROB state, so throughput is not widened beyond one instruction per cycle. On these loop-heavy microkernels, that backend bookkeeping cost shows up directly in cycles.
For super-ooo, missing pairwise entries come from signature-invalid runs, not from omitted data collection. The benchmark script records the cycle count, marks signature-invalid runs, and excludes them from speedup math by design.
Super-OOO in this revision is a failed attempt from my side because the design complexity got too high to stabilize quickly. I need to revisit single-issue OOO first, dig deeper there, and then come back to super-OOO.
Running the Variants
Prerequisites
All variants require the RISC-V GCC toolchain and simulation tools:
# Check installed versions
riscv64-unknown-elf-gcc --version
iverilog -v
verilator --version
python3 --version
spike --help | head -5
qemu-riscv32 --version
Building and Simulating
Each variant has the same Makefile structure. Navigate to the variant directory and use these targets:
cd rv32i-sc # or rv32i-mc, rv32i-pipe, etc.
# Build with Iverilog
make iverilog-prog
# Run simulation
vvp tb_program_sim.vvp -vcd
# View waveform
gtkwave tb_program.vcd &
# Build and run with Verilator (faster)
make verilator-prog-sim
Running RISC-V ISA Tests
All variants pass the official rv32ui and rv32um test suites. To run them:
# Set path to riscv-tests repository
export RISCV_TESTS=/home/jagadeesh97/rv32i/riscv-tests
# Navigate to variant
cd rv32i-sc
# Run all rv32ui tests (37 tests)
for test in add addi and andi auipc beq bge bgeu blt bltu bne fence_i jal jalr \
lb lbu lh lhu lui lw ori or sb sh slt slti sltiu sltu sll slli \
sra srai srl srli sub xor xori; do
riscv64-unknown-elf-gcc -march=rv32i -mabi=ilp32 -nostdlib \
-I$RISCV_TESTS/env/p -I$RISCV_TESTS/isa/macros/scalar \
-T test_hex/link_at_0.ld -o /tmp/${test}.elf \
$RISCV_TESTS/isa/rv32ui/${test}.S
python3 scripts/run_riscv_test.py $test /tmp/${test}.elf 2>&1 | grep -E "PASS|FAIL"
done
# Run all rv32um tests (8 tests)
for test in mul mulh mulhsu mulhu div divu rem remu; do
riscv64-unknown-elf-gcc -march=rv32im -mabi=ilp32 -nostdlib \
-I$RISCV_TESTS/env/p -I$RISCV_TESTS/isa/macros/scalar \
-T test_hex/link_at_0.ld -o /tmp/${test}.elf \
$RISCV_TESTS/isa/rv32um/${test}.S
python3 scripts/run_riscv_test.py $test /tmp/${test}.elf 2>&1 | grep -E "PASS|FAIL"
done
All tests should print PASS.
Running Any C Program
The testbench supports arbitrary C programs compiled for RV32I:
cd rv32i-sc
# Compile your C program
riscv64-unknown-elf-gcc -march=rv32i -mabi=ilp32 -nostdlib -Ttext 0x0 \
-o myprogram.elf myprogram.c
# Convert to hex
python3 scripts/elf2hex.py myprogram.elf hex/inst_mem.hex hex/data_mem.hex
# Simulate
make iverilog-prog
vvp tb_program_sim.vvp -vcd
# Check results
cat tb_program_results.txt
Or use the shortcut:
make c-run C_SRC=scripts/fibonacci.c ELF=fibonacci.elf
Cross-Checking with Spike and QEMU
To verify RTL output against golden models:
# Run RTL, Spike, and QEMU on the same C program and compare outputs
python3 scripts/crosscheck_qemu_spike.py scripts/fibonacci.c --words 16
This script:
- Compiles the C program for RTL (address 0x0)
- Compiles for Spike/QEMU (address 0x80000000)
- Runs all three simulations
- Compares memory dumps word-by-word
Example output:
RTL, QEMU, and Spike outputs match for all 16 words.
Running Benchmarks
The benchmark suite runs all kernels across all variants and generates a performance report:
cd /home/jagadeesh97/rv32i
# Run full benchmark suite (takes ~30 minutes)
python3 benchmark/run_benchmarks.py \
--gcc riscv64-unknown-elf-gcc \
--spike /home/jagadeesh97/riscv/bin/spike \
--opt-level -O0
# Results saved to:
# benchmark/results/metrics.csv
# benchmark/results/summary.csv
# benchmark/results/pairwise.csv
# benchmark/results/report.md
Options:
--opt-level: -O0, -O1, -O2, -O3 (default -O0)--keep-logs: Save full per-cycle simulation logs--sim-timeout: Timeout per simulation in seconds (default 900)--strict: Fail if any signature check fails
The benchmark script:
- Compiles each kernel with Spike as reference
- Builds each variant’s Iverilog testbench
- Runs all kernel/variant combinations
- Validates outputs against Spike signatures
- Computes IPC, CPI, speedup metrics
- Generates markdown report with tables
Notes on Implementation Quality
The single-cycle, multi-cycle, pipelined, and superscalar variants are solid implementations that pass all tests and deliver expected performance characteristics.
The single-issue OOO variant is functionally correct (passes ISA tests) but slower than pipe on this benchmark set. The current design is still 1-wide at key points, so rename and ROB machinery add control overhead without widening retirement throughput.
The super-OOO variant is a failed attempt in this revision. It combines dual-dispatch, dual-issue, dual-commit, and wide wakeup paths, and it is currently not stable enough across the benchmark set.
Next step is to revisit single-issue OOO first and dig deeper, then return to super-OOO after that baseline is stronger.
File Structure
rv32i/
├── rv32i-sc/ Single-cycle variant
├── rv32i-mc/ Multi-cycle variant
├── rv32i-pipe/ Pipelined variant
├── rv32i-superscalar/ 2-way superscalar variant
├── rv32i-ooo/ Single-issue OOO variant
├── rv32i-super-ooo/ Dual-issue OOO variant
├── benchmark/
│ ├── kernels/ Microbenchmark C sources
│ ├── results/ CSV and markdown reports
│ └── run_benchmarks.py
├── riscv-tests/ Official RISC-V test suite
└── coremark/ CoreMark benchmark (optional)
Each variant directory:
rtl/
core/ Core pipeline components
mem/ Memory subsystem
top/ Top-level integration
tb/ Testbenches (instructions, program)
scripts/ ELF to hex, cross-check scripts
hex/ Instruction and data memory images
test_hex/ ISA test infrastructure
Makefile
README.md
Summary
This project provides a complete spectrum of RV32I implementations from the simplest combinational design to a complex dual-issue out-of-order machine. The shared verification infrastructure (ISA tests, cross-check scripts, benchmark suite) ensures apples-to-apples comparison.
The pipelined and superscalar variants represent practical, working designs suitable for embedded or educational use. The OOO variants demonstrate advanced concepts but have implementation issues that need resolution. All variants pass the RISC-V compliance tests, confirming correct instruction semantics.
The benchmark results highlight the importance of not just microarchitectural sophistication but also correct implementation. Adding complexity (OOO scheduling, dual-issue) only improves performance when the additional mechanisms are correctly tuned. Otherwise, the overhead of complexity can degrade performance (as seen with the OOO variant) or cause outright incorrectness (as with super-OOO).