VISION: Verilog for Image Processing and Simulation-based Inference Of Neural Networks


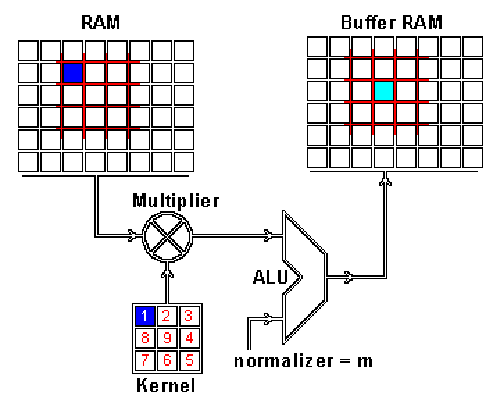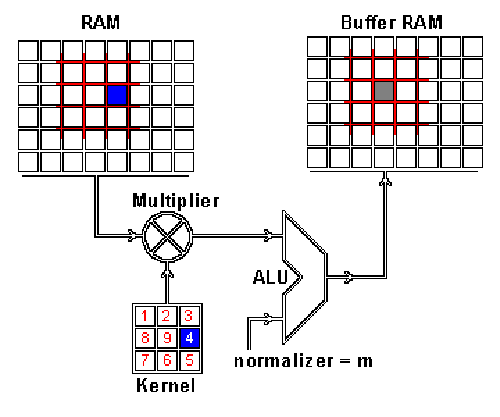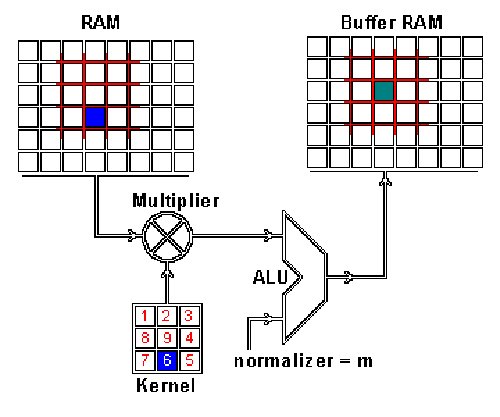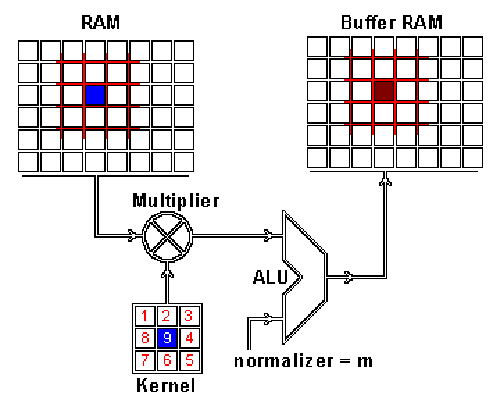
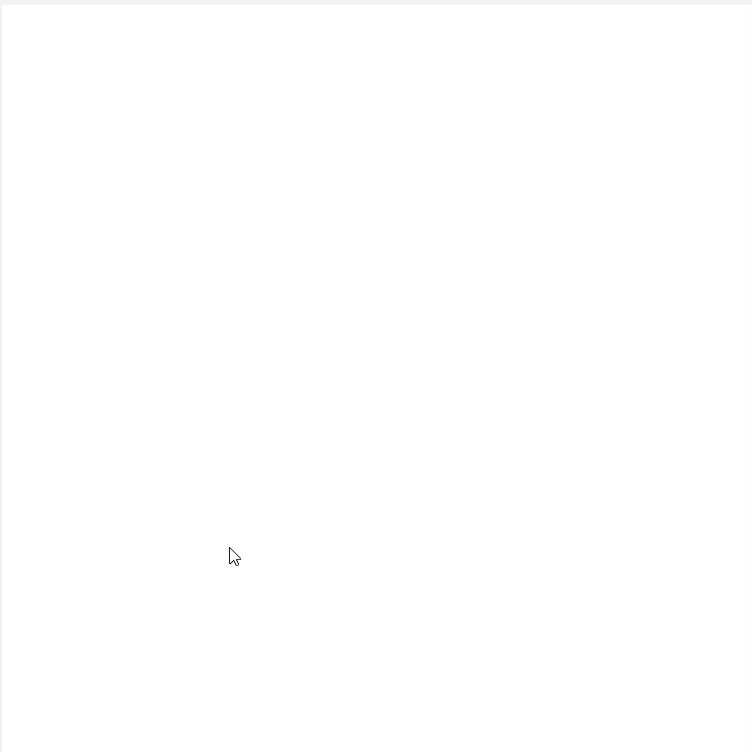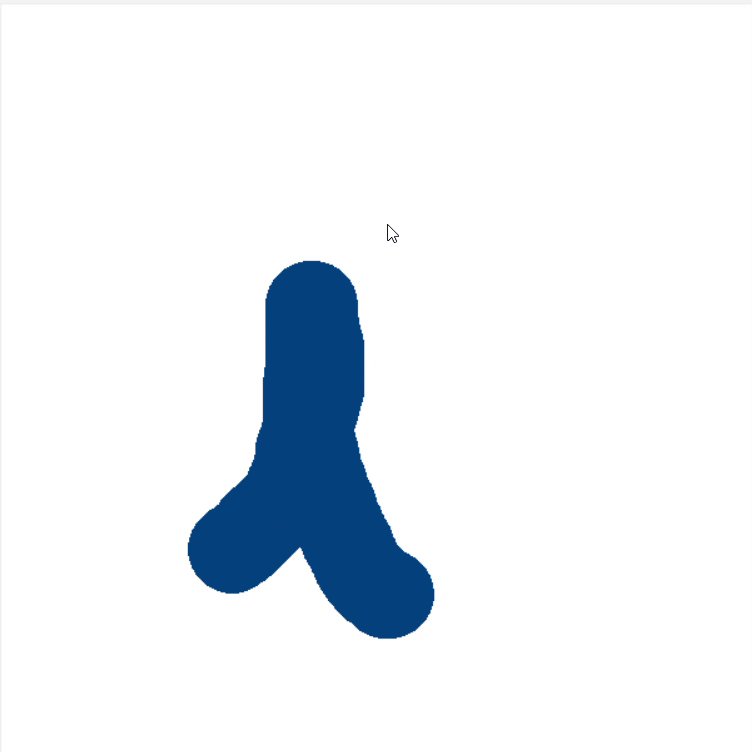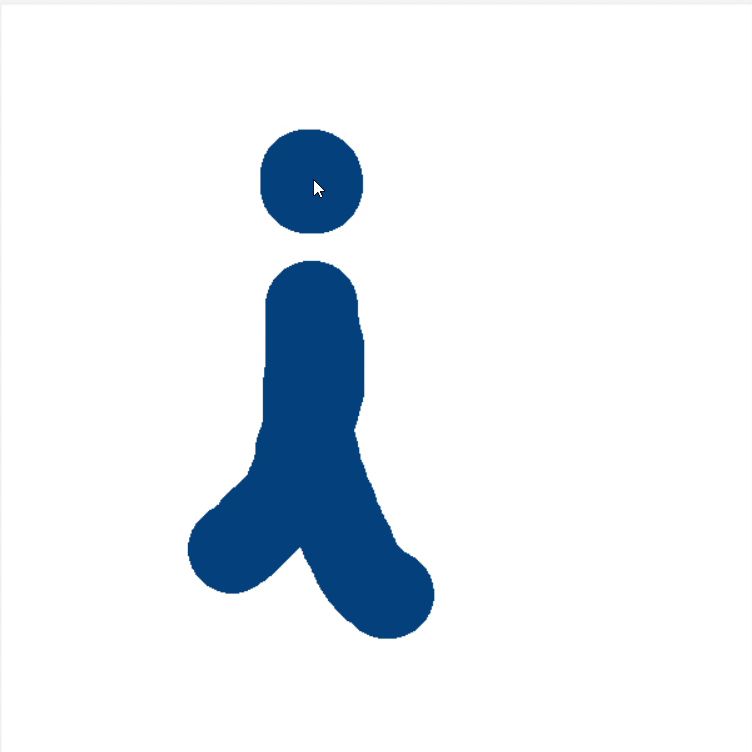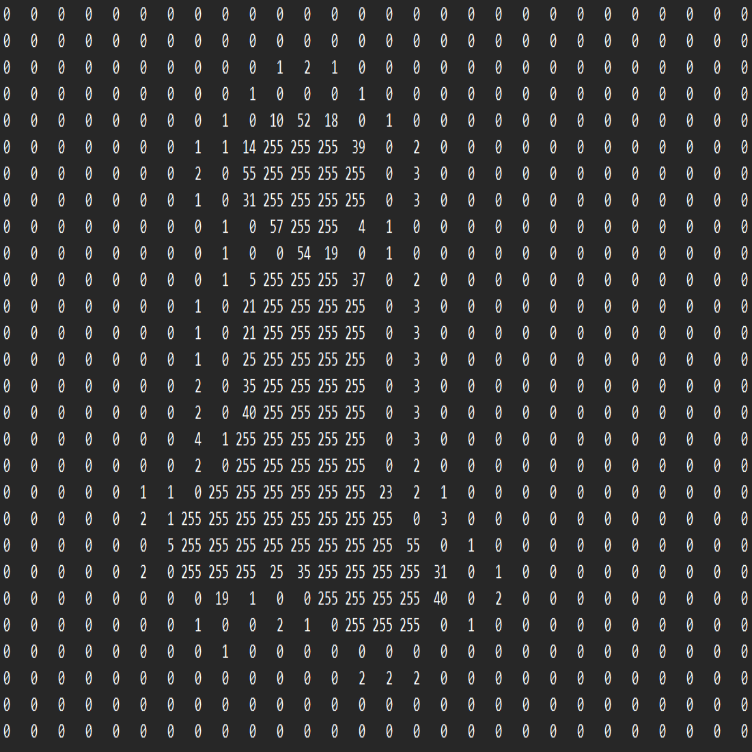
| Repository | Mummanajagadeesh/ViSiON |
|---|---|
| Start Date | Dec 2024 |
Note: The following projects evolved in parallel under a single umbrella of compute architectures, hardware acceleration, and RTL-level optimization. While not all efforts directly converge to a single product, each branch was intentionally explored to understand performance–accuracy–area trade-offs across digital design, ML inference, verification, and physical implementation flows.
VISION: Verilog for Image Processing and Simulation-Based Inference of Neural Networks
Timeline Overview
Dec 2024 Initiated with hardware-based image rotation experiments (“ROVER”). Early focus: geometric transforms, color transforms, filtering, enhancement.
Feb 2025 – May 2025 Expansion into MNIST preprocessing pipeline in RTL. Development of fixed-point MLP classifier → evolved into NeVer.
June 2025 Initial sine approximation core; early experimentation with shift-add based math implementations.
Aug 2025 Transition to RGB datasets and CNNs (CIFAR-10). Began systolic-array based acceleration and structured microarchitecture exploration.
Nov 2025 Separated CORDIC core and wrappers. Introduced full multi-mode CORDIC and formal verification using SymbiYosys.
Dec 2025 AXI-Stream refinements and OpenCL-based functional validation for ImProVe toolkit.
Jan 2026 Extension of CNN accelerator to ARM-based FPGA deployment (Bharat AI SoC Challenge). Integrated AXI4-Lite, AXI-Stream, DMA workflows, and HLS explorations.
INT8 Fixed-Point CNN Hardware Accelerator and Image-Processing Suite
- Designed a synthesizable shallow Res-CNN for CIFAR-10, Pareto-optimal among 8 CNNs for parameter memory, accuracy & FLOPs
- Built systolic-array PEs with 8-bit CSA–MBE MACs, FSM-based control, 2-cycle ready/valid handshake, and verified TB operation
- Performed PTQ/QAT (Q1.31→Q1.3) analysis; Q1.7 PTQ retained ∼84% accuracy (<1% loss) with 4x smaller (∼52kB) memory footprint
- Auto-generated 14 coeff & 3 RGB ROMs via TCL/Py automation; validated TF/FP32–RTL consistency and automated inference execution
- Implemented AXI-Stream DIP toolkit (edge, denoise, filter, enhance) with pipelined RTL & FIFO backpressure handling
- MLP classifier on (E)MNIST (>75% acc.) with GUI viz; Automated preprocessing & inference with TCL/Perl
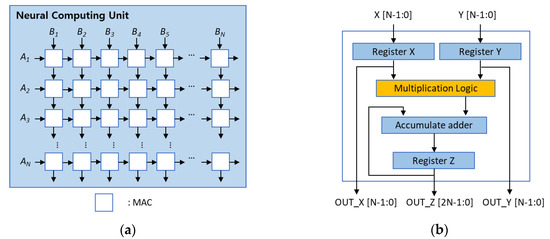
3-Stage Pipelined Systolic Array-Based MAC Microarchitecture
- Benchmarked six 8-bit signed adders-multipliers via identical RTL2GDS Sky130 flow to isolate arithmetic-level post-route PPA trade-offs
- 3-stage pipelined systolic MAC (CSA-MBE), achieving ↓66.3% delay; ↑3.1× area efficiency; ↓82.2% typical power vs naïve conv3 baseline
- Used a 2D PE-grid structure for convolution (verified 0/same padding modes) and optimized GEMM (reducing power by 44.6%; N = 3)
- Added a 648-bit scan chain across all pipeline/control registers, enabling full DFT/ATPG testability with only +14.5% cell overhead
Design & Formal Verification of Parameterizable Fixed-Point CORDIC IP
- Implemented shift-add datapath with all 6 modes rotation/vectoring (circular/linear/hyperbolic); width/iter/angle frac/output width–shift scaling swept across configs
- Built trig/mag/atan2/mul/div/exp wrappers; observed ∼e-5 RMS (@32b, 16iter) baseline vs double-precision references
- Proved handshake, deadlock-free bounded liveness, range safety, symmetry & monotonicity via SystemVerilog assertions (SymbiYosys/Yices2)
- Auto-generated atan tables & param files via Python; FuseSoC-packaged core with documented sensitivity, error trends & failure regions
- Built drop-in core variants (pipelined/SIMD/multi-issue); implemented a QAM16 demodulator using the CORDIC core
Expanded Project Overview
Phase 1 — From ROVER to ImProVe (Image Processing Practice Platform)
The project began with hardware-based image rotation. After eliminating non-synthesizable constructs, rotation, geometric transforms, color transformations, filtering, and enhancement algorithms were implemented fully in RTL.
This evolved into ImProVe (IMage PROcessing using VErilog) — initially developed as a practice platform to understand streaming datapaths and pipeline scheduling. The toolkit included:
- Edge detection
- Denoising
- Filtering and enhancement
- Geometric transforms
- Thresholding and contrast adjustment
Applications explored (as practice implementations):
- Label detection
- Document scanner pipeline
- Stereo depth estimation
AXI-Stream compliant interfaces were implemented with FIFO-based backpressure control. Later, OpenCL was used for functional validation against software references.
Phase 2 — NeVer: Neural Network in Verilog
Around Feb 2025, preprocessing logic for MNIST was designed:
- User input via Tkinter GUI
- RTL-based thresholding
- Contrast scaling
- Character detection
- Cropping
- Resizing
- Rotation correction
This created a full hardware preprocessing workflow.
A fixed-point MLP classifier was developed using weight scaling (linear advantage of MLPs exploited). It was later extended to EMNIST.
Observations:
- Accuracy >75%
- Noticeable drop due to weight scaling instead of structured quantization
- Generalization issues from real handwritten inputs (distribution mismatch)
Extensive automation was introduced:
- TCL/Perl scripts for inference flow
- Python-based dataset handling
- Automated testbench execution
This body of work formed NeVer, completed around May 2025.
Phase 3 — INT8 CNN & Systolic Acceleration (CIFAR-10)
Around Aug 2025, the direction shifted to RGB image classification using CIFAR-10 and CNNs.
Training-level optimizations:
- Architectural exploration (multiple CNN variants)
- BatchNorm experiments
- Dense layer restructuring
- BatchNorm fusion
Quantization:
- PTQ and QAT experiments
- Final deployment using Q1.7 format
- <1% accuracy degradation
RTL Implementation:
- Layer-by-layer validation using Python golden models
- Manual ROM generation via Python
- Deterministic verification across layers
Compute Acceleration:
- Pipelined systolic array-based matrix multiplication
- Dedicated convolution and GEMM cores
- 2-cycle handshake protocol
Arithmetic Selection Study:
- Multiple adder and multiplier architectures
- RTL-to-GDS flow using Sky130 (OpenLane)
- Not intended as production tapeout; used to compare latency, area, and power trade-offs
- First experience with open-source RTL2GDS toolchains
Phase 4 — Formalized Math Acceleration: CORDIC IP
Rotation experiments originally required sine approximation. An early sine core was implemented in June 2025.
By Nov 2025, the design was restructured:
- Core–wrapper separation
- Support for circular, linear, hyperbolic modes
- Trig, exp, log, div, mul implementations via wrappers
Formal verification (first exposure to formal methods):
- Verified 2-cycle handshake correctness
- Deadlock-free guarantees
- Bounded liveness
- Mathematical properties within tolerances
Formal tools used:
- SymbiYosys
- Yices2
This marked the first structured formal verification effort in the project.
Phase 5 — ARM-Based FPGA Deployment (Bharat AI SoC Challenge, Jan 2026)
Extension of CIFAR CNN project to ARM-based FPGA (Zynq-7000 class).
Architecture:
- Tiling-based convolution accelerator
- MAC PEs + line buffers
- AXI4-Lite (AXI-MM subset) for weights
- AXI-Stream for image input
- Planned feature-map streaming
- DDR-DMA with FIFO decoupling
Software Baseline:
- PYNQ-based NumPy implementation
- keras2c
- hls4ml (Vitis HLS) exploration
Quantization & Toolflow:
- Brevitas 4-bit QAT
- QONNX → FINN conversion
- Achieved synthesis metrics (~11.5k LUT, 3 DSP, 22 BRAM @100 MHz)
Manual streaming-based loading replaced Python-generated ROM initialization for better deployment flexibility.
First convolution layer implemented on board as proof-of-concept.
Unified Theme
Across all branches—ImProVe, NeVer, CNN acceleration, systolic microarchitecture, CORDIC IP, and FPGA deployment—the consistent focus has been:
- Fixed-point arithmetic design
- Pipelined microarchitectures
- Streaming interfaces (AXI-Stream)
- Hardware–software co-validation
- Quantization vs scaling trade-offs
- Automation of inference workflows
- Exploration of arithmetic-level PPA trade-offs
- Introduction to physical design and formal verification
The work collectively represents iterative exploration of hardware-aware ML acceleration, rather than a single linear product.