
VISION: Verilog for Image Processing and Simulation-based Inference Of Neural Networks


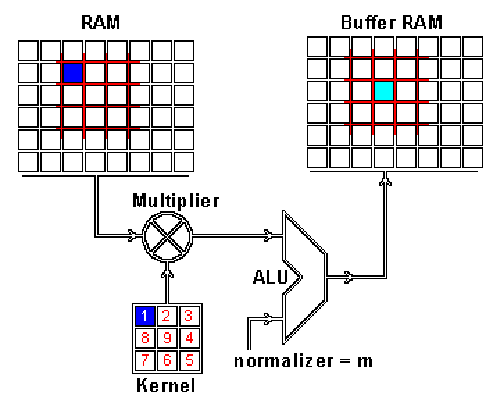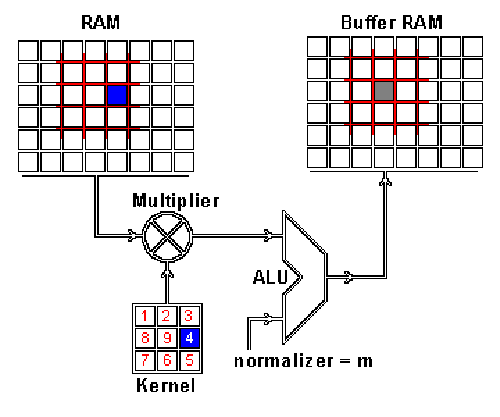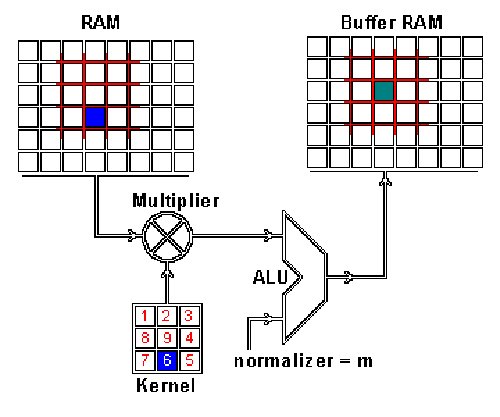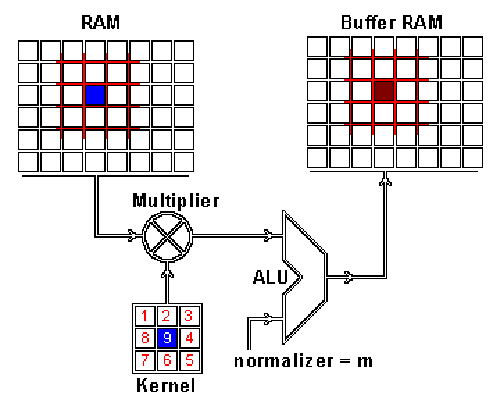
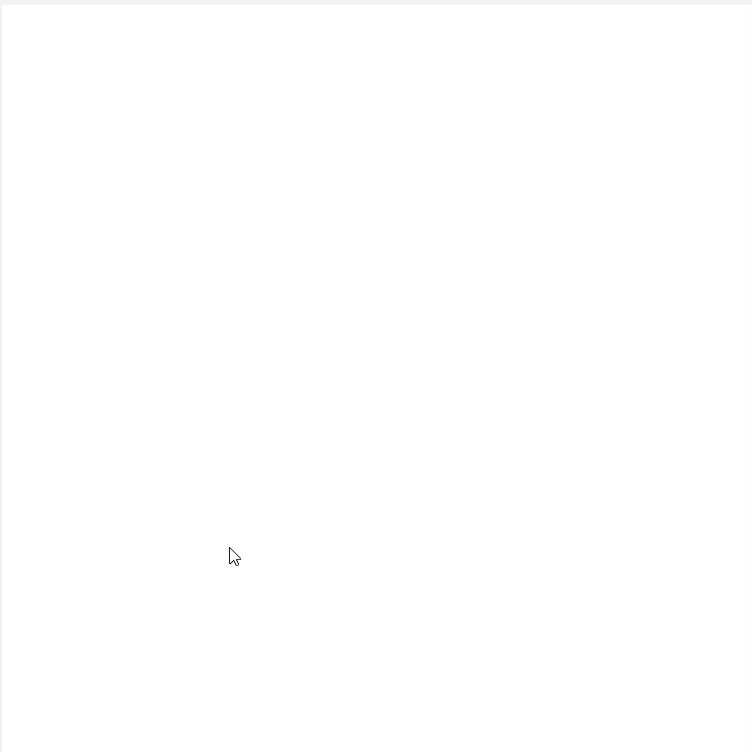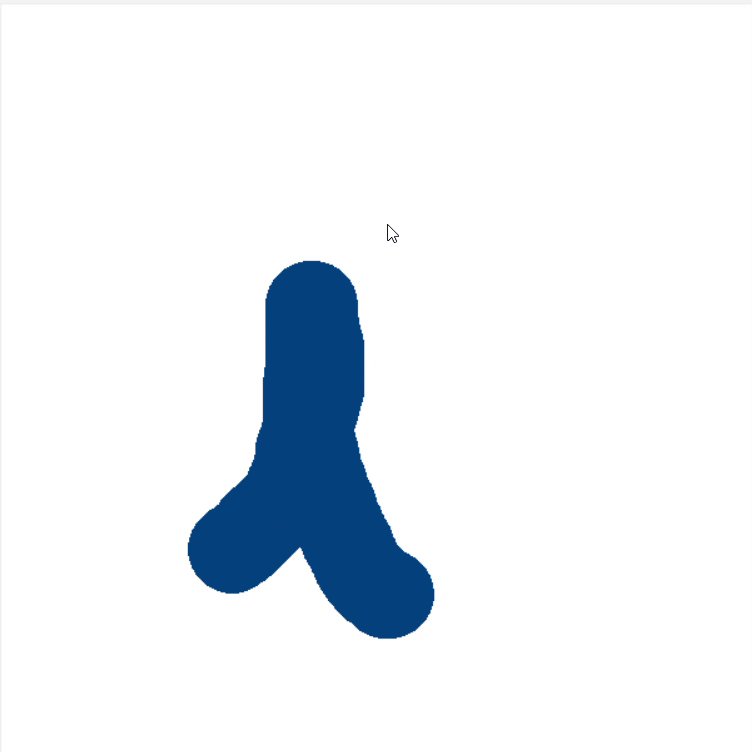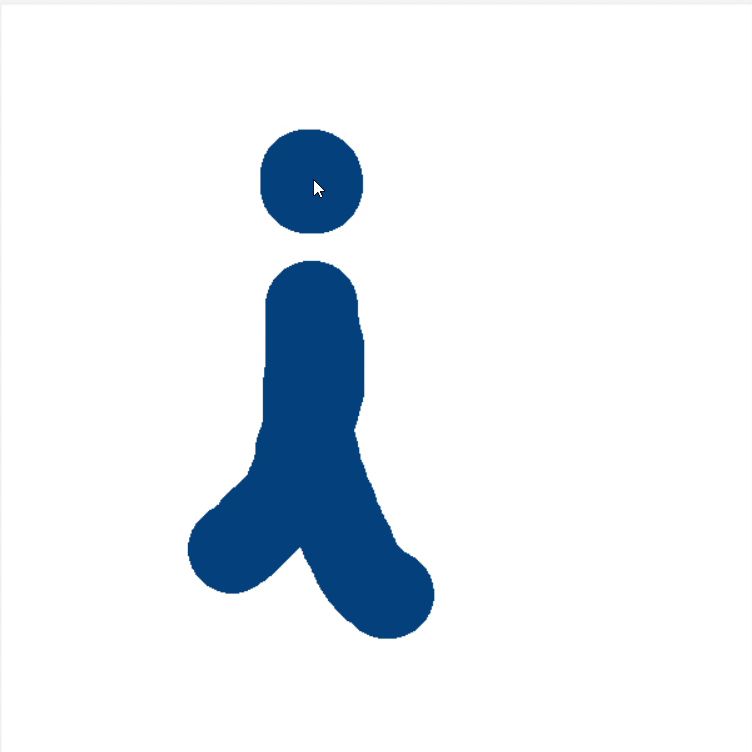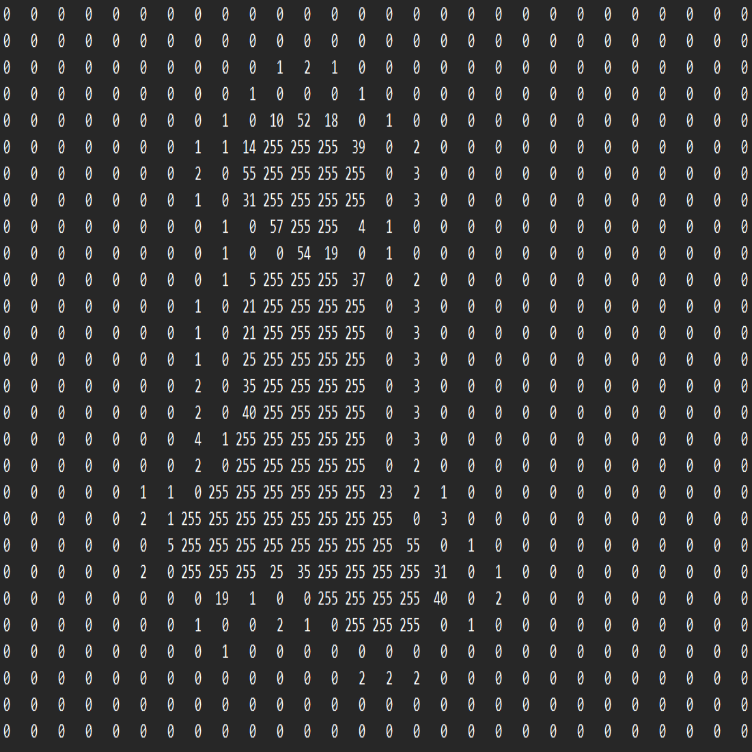
| Repository | Mummanajagadeesh/ViSiON |
|---|---|
| Start Date | Dec 2024 |
Note: The following projects evolved in parallel under a single umbrella of compute architectures, hardware acceleration, and RTL-level optimization. While not all efforts directly converge to a single product, each branch was intentionally explored to understand performance–accuracy–area trade-offs across digital design, ML inference, verification, and physical implementation flows.
VISION: Verilog for Image Processing and Simulation-Based Inference of Neural Networks
Timeline Overview
" I tried to ImProVe, but NeVer really did - so I MOVe-d on ¯\_(ツ)_/¯ “
Dec 2024 — ImProVe & Early Image Processing
Work began with ImProVe (IMage PROcessing using VErilog), a streaming RTL toolkit developed while experimenting with hardware image rotation (“ROVER”). Focus areas included:
- Geometric transforms (rotation, scaling)
- Color space transforms
- Edge detection and filtering
- Image enhancement pipelines
These designs were later implemented as AXI-Stream compatible RTL pipelines with FIFO-based backpressure handling. The toolkit served as a practical platform for learning streaming datapath design and pipeline scheduling.
Feb 2025 – May 2025 — NeVer: Neural Network in Verilog
The project expanded into hardware preprocessing for handwritten digit recognition.
An RTL preprocessing pipeline for MNIST was implemented, including:
- Thresholding
- Contrast normalization
- Character detection
- Cropping and centering
- Rotation correction
- Resizing
This preprocessing chain fed a fixed-point MLP classifier, implemented entirely in RTL. The system evolved into NeVer (NEural NEtwork in VERilog).
Key characteristics:
- Fixed-point inference
- Automated inference flow using TCL/Perl scripts
- Dataset handling and preprocessing automation
75% accuracy on MNIST/EMNIST datasets
June – July 2025 — MOVe: Math Ops in Verilog
While implementing image rotation and neural network operators, a need arose for hardware math primitives. This led to the creation of MOVe (Math Ops in Verilog) — a collection of arithmetic accelerators implemented entirely in RTL.
Implemented components included:
- Shift-add sine approximation cores
- CORDIC prototypes for trigonometric functions
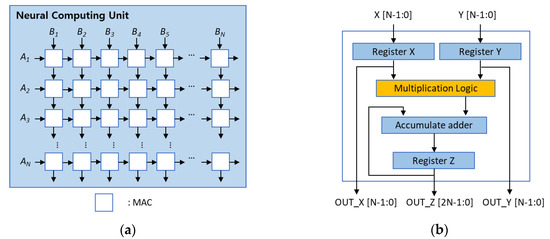
- MAC units for neural network operations
- Early exploration of posit arithmetic
- Fixed-point arithmetic wrappers
- Custom arithmetic pipelines for matrix operations
This work focused on numerical representation and hardware-friendly math implementations, forming the arithmetic foundation for later CNN accelerators.
Aug 2025 — CNN Acceleration & Systolic Compute
The focus shifted to RGB image classification using CIFAR-10.
Major developments:
- Design of several CNN architectures with Pareto analysis across accuracy, parameters, and FLOPs
- Defined an FoM to compare CNN architectures
- Quantization experiments (PTQ and QAT)
- Final deployment using INT8 (Q1.7) inference
Hardware acceleration efforts included:
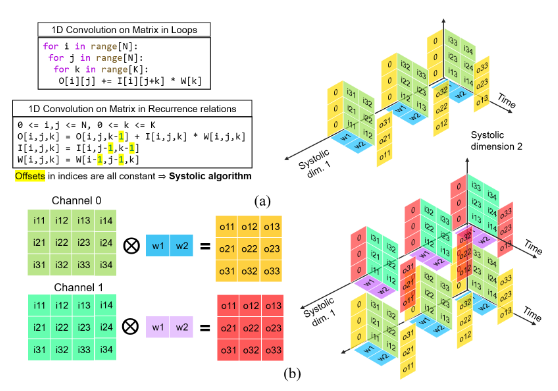
- Systolic-array based matrix multiplication
- Dedicated MAC microarchitectures
- GEMM-based convolution implementations
- Tiling strategies for convolution layers
RTL implementations were validated layer-by-layer against Python reference models.
Nov 2025 — CORDIC IP Formalization
The earlier math experiments from MOVe were reorganized into a standalone CORDIC IP project.
Enhancements included:
- Separation of core iteration engine and wrappers
- Support for circular, linear, and hyperbolic modes
- Implementation of trig, magnitude, atan2, exp, div, and mul functions
- Formal verification using SymbiYosys + Yices2
This became the dedicated CORDIC IP project later integrated into other DSP systems.
Dec 2025 — ImProVe Streaming Refinements
The ImProVe toolkit was extended with:
- Improved AXI-Stream pipeline scheduling
- FIFO-based backpressure handling
- Additional image processing operators
Functional validation was performed using OpenCL software models to cross-check RTL behavior.
Jan 2026 — FPGA Deployment (Bharat AI SoC Challenge)
The CNN accelerator work was extended to Zynq-7000 FPGA deployment.
Key system components:
- AXI-Stream dataflow pipelines
- AXI4-Lite control interfaces
- DMA-based feature map transfers
- ARM–FPGA integration
Additional experimentation included:
- HLS implementations (Vitis HLS / hls4ml / FINN)
- Comparison of manual RTL accelerators vs HLS-generated designs
- Hardware/software co-validation on the target FPGA platform
INT8 Fixed-Point CNN Hardware Accelerator and Image-Processing Suite
- “Designed and evaluated multiple CIFAR-10 CNNs, selecting a Pareto-optimal 6-layer residual model balancing accuracy (~84%), parameter memory (~52 kB), and compute (~12–13 M FLOPs) for hardware deployment”
- “Implemented a tiling-based convolution/GEMM accelerator with reusable MAC PEs and line-buffered dataflow; integrated AXI4-Lite control + AXI-Stream/DMA data movement; verified end-to-end via RTL testbenches against Python reference models”
- “Developed pipelined processing elements using 8-bit Booth–Kogge MACs, with FSM-based control and a 2-cycle ready/valid handshake, ensuring timing-clean and scalable datapath operation”
- “Performed quantization studies (PTQ/QAT) from FP32 (Q1.31) to fixed-point (Q1.7), achieving ~4× memory reduction with <1% accuracy loss; validated TensorFlow FP32 to RTL numerical consistency”
- “Built automation flows (TCL/Python) for ROM/weight generation, testbench stimulus, and inference execution; generated coefficient memories and ensured deterministic layer-by-layer verification”
- “Implemented a streaming image-processing toolkit (AXI-Stream) including edge detection, filtering, denoising, and enhancement, with pipelined RTL and FIFO-based backpressure handling; included MLP-based (E)MNIST classifier with automated preprocessing/inference”
Pipelined Systolic Array for GEMM/Conv2D with MAC PPA Study (Sky130 OpenLane)
- Designed parameterized output-stationary 2D systolic array for signed 8-bit GEMM/Conv2D with wavefront scheduling and pipelined PEs
- Implemented im2col-based Conv2D mapping onto GEMM core (4×16×36), achieving 42.47 MAC/cycle (99.5% peak) at 66.3% PE utilization
- Explored 9 MAC architectures (Array/Baugh/Booth × RCA/Kogge/CSA) via full RTL-to-GDSII (OpenLane, sky130_fd_sc_hd); achieved 100 MHz timing closure with post-route STA correlation and 0 DRC/LVS violations
- Quantified PPA tradeoffs: Booth+RCA 15.8k µm² / 537 cells (min area); Array+Kogge 5.68 ns (~176 MHz, max Fmax); Kogge ~4–5% faster at ~20% higher power; CSA ~67% larger and ~2× power with no timing gain
- Designed ping-pong SRAM tiled GEMM with DMA-backed data movement (1-cycle buffer swap), enabling overlap of load and compute
- Implemented direct-mapped tile cache (tag+valid) achieving 93.75% hit rate; verified across 240+ tests (GEMM/Conv, random/boundary/burst/multi-tile), confirming functional correctness and linear systolic scaling (K+M+N−2)
Design & Formal Verification of Parameterizable Fixed-Point CORDIC IP
- “Implemented shift-add datapath with all 6 modes rotation/vectoring (circular/linear/hyperbolic); width/iter/angle frac/output width–shift scaling swept across configs”
- “Built trig/mag/atan2/mul/div/exp wrappers; observed ∼e-5 RMS (@32b, 16iter) baseline vs double-precision references”
- “Proved handshake, deadlock-free bounded liveness, range safety, symmetry & monotonicity via SystemVerilog assertions (SymbiYosys/Yices2)”
- “Auto-generated atan tables & param files via Python; FuseSoC-packaged core with documented sensitivity, error trends & failure regions”
- “Variants: pipelined/SIMD/multi-issue; Systems: radix-2 FFT/IFFT, DPLL, Sigma-Delta ADC Front-End, QAM16 receiver (Costas carrier + Gardner timing recovery)”
Expanded Project Overview
Phase 1 — From ROVER to ImProVe (Image Processing Practice Platform)
The project began with hardware-based image rotation. After eliminating non-synthesizable constructs, rotation, geometric transforms, color transformations, filtering, and enhancement algorithms were implemented fully in RTL.
This evolved into ImProVe (IMage PROcessing using VErilog) — initially developed as a practice platform to understand streaming datapaths and pipeline scheduling. The toolkit included:
- Edge detection
- Denoising
- Filtering and enhancement
- Geometric transforms
- Thresholding and contrast adjustment
Applications explored (as practice implementations):
- Label detection
- Document scanner pipeline
- Stereo depth estimation
AXI-Stream compliant interfaces were implemented with FIFO-based backpressure control. Later, OpenCL was used for functional validation against software references.
Phase 2 — NeVer: Neural Network in Verilog
Around Feb 2025, preprocessing logic for MNIST was designed:
- User input via Tkinter GUI
- RTL-based thresholding
- Contrast scaling
- Character detection
- Cropping
- Resizing
- Rotation correction
This created a full hardware preprocessing workflow.
A fixed-point MLP classifier was developed using weight scaling (linear advantage of MLPs exploited). It was later extended to EMNIST.
Observations:
- Accuracy >75%
- Noticeable drop due to weight scaling instead of structured quantization
- Generalization issues from real handwritten inputs (distribution mismatch)
Extensive automation was introduced:
- TCL/Perl scripts for inference flow
- Python-based dataset handling
- Automated testbench execution
This body of work formed NeVer, completed around May 2025.
Phase 3 — INT8 CNN & Systolic Acceleration (CIFAR-10)
Around Aug 2025, the direction shifted to RGB image classification using CIFAR-10 and CNNs.
Training-level optimizations:
- Architectural exploration (multiple CNN variants)
- BatchNorm experiments
- Dense layer restructuring
- BatchNorm fusion
Quantization:
- PTQ and QAT experiments
- Final deployment using Q1.7 format
- <1% accuracy degradation
RTL Implementation:
- Layer-by-layer validation using Python golden models
- Manual ROM generation via Python
- Deterministic verification across layers
Compute Acceleration:
- Pipelined systolic array-based matrix multiplication
- Dedicated convolution and GEMM cores
- 2-cycle handshake protocol
Arithmetic Selection Study:
- Multiple adder and multiplier architectures
- RTL-to-GDS flow using Sky130 (OpenLane)
- Not intended as production tapeout; used to compare latency, area, and power trade-offs
- First experience with open-source RTL2GDS toolchains
Phase 4 — Formalized Math Acceleration: CORDIC IP
Rotation experiments originally required sine approximation. An early sine core was implemented in June 2025.
By Nov 2025, the design was restructured:
- Core–wrapper separation
- Support for circular, linear, hyperbolic modes
- Trig, exp, log, div, mul implementations via wrappers
Formal verification (first exposure to formal methods):
- Verified 2-cycle handshake correctness
- Deadlock-free guarantees
- Bounded liveness
- Mathematical properties within tolerances
Formal tools used:
- SymbiYosys
- Yices2
This marked the first structured formal verification effort in the project.
Phase 5 — FPGA Deployment & HLS Exploration (Bharat AI SoC Challenge, Jan 2026)
The CNN accelerator work was extended to ARM-based FPGA deployment on Zynq-7000 (xc7z020) as part of the Bharat AI SoC Challenge (ARM + C2S India).
The objective was to evaluate hardware CNN inference under realistic FPGA resource constraints while comparing manual RTL accelerators with HLS-generated implementations.
Deployment Architecture
The system used a PS–PL co-design architecture.
ARM Cortex-A9 (PS)
│
AXI4-Lite (control)
│
CNN Inference Accelerator (PL)
│
AXI-Stream / AXI Master
│
DDR Memory (feature maps + images)
Key integration components:
- AXI4-Lite control interface
- AXI master DMA for image reads
- AXI-Stream pipelines for feature-map processing
- FIFO decoupling between memory and compute units
The accelerator operated on 32×32×3 CIFAR-10 images and returned the predicted class.
Network Architecture
A compact Mini-ResNet CNN was implemented.
Input 32x32x3
Block 1:
conv3x3 (3 → 28)
conv3x3 (28 → 28) + conv1x1 shortcut
maxpool2x2
Block 2:
conv3x3 (28 → 56)
conv3x3 (56 → 56) + conv1x1 shortcut
maxpool2x2
Head:
GlobalAvgPool → Dense(56 → 10)
Weights were stored as Q1.7 fixed-point integers, reducing memory footprint while maintaining classification accuracy.
Quantization Results
| Model Format | Accuracy |
|---|---|
| FP32 training | ~85% |
| Q1.7 inference | ~84% |
| Accuracy loss | < 1% |
Quantization reduced parameter storage to approximately 52 kB, enabling full weight storage within FPGA memory.
HLS Implementation
The CNN inference pipeline was implemented in Vitis HLS using a manually optimized C++ kernel.
Development stages:
- Python reference model
- Standalone C++ inference
- Vitis HLS kernel generation
- FPGA synthesis and resource analysis
The HLS kernel used:
ap_fixed<16,8> arithmetic
AXI master interface for image input
AXI-Lite control interface
Function interface:
void cifar10_infer(ap_fixed<16,8> image_in[3072], ap_uint<4>* pred_out);
Resource Utilization (Zynq-7020, 100 MHz target)
| Resource | Used | Available | Utilization |
|---|---|---|---|
| LUT | 18,379 | 53,200 | 34% |
| FF | 11,014 | 106,400 | 10% |
| BRAM | 243 | 280 | 86% |
| DSP | 22 | 220 | 10% |
Estimated Fmax:
136.99 MHz
The design successfully fit within the FPGA fabric while maintaining the target throughput.
Manual Optimization to Fit FPGA
The initial HLS synthesis did not fit the FPGA:
LUT usage: 70,353 (132%)
The main issue came from runtime index multiplications inside the maxpool2x2 blocks.
HLS generated 64-bit multipliers and large mux trees, dramatically increasing LUT usage.
Problematic blocks:
grp_maxpool2x2_16_16_56_s
grp_maxpool2x2_32_32_28_s
Optimization Strategy
Index expressions were replaced with loop-carried address increments.
Instead of:
oh*2*W*C
ow*2*C
the design used:
base pointers + constant stride increments
This allowed HLS to generate adders instead of multipliers.
Result
| Metric | Before Fix | After Fix |
|---|---|---|
| LUT usage | 70,353 | 18,379 |
| Utilization | 132% | 34% |
| Maxpool LUT cost | ~27k | ~2.8k |
The optimized design successfully fit on the xc7z020 while maintaining the original CNN accuracy (~84%).
HLS vs Manual RTL Exploration
The project also compared multiple accelerator approaches:
| Approach | Purpose |
|---|---|
| Manual RTL CNN accelerator | Fine-grained microarchitecture control |
| HLS CNN kernel | Rapid hardware generation |
| PYNQ NumPy baseline | Software reference |
| FINN / hls4ml experiments | Alternative ML hardware toolflows |
This comparison highlighted trade-offs between:
- manual RTL optimization
- HLS productivity
- resource efficiency
- design iteration speed
Key Observations
- Fixed-point Q1.7 inference preserves ~84% CIFAR-10 accuracy
- Manual restructuring of HLS code is often required to prevent unintended hardware generation
- Memory indexing patterns strongly influence hardware resource usage
- AXI-based streaming allows efficient PS–PL co-processing on Zynq
The deployment validated the feasibility of hardware CNN inference within the constraints of mid-range FPGA platforms.
Current Status / TLDR
- “Explored 8 CNN architectures on CIFAR-10; selected Pareto-optimal ResNet-style model (52k params, 12.6M FLOPs, 80-84% accuracy) for hardware deployment.”
- “Applied PTQ and QAT quantization (Q1.7 fixed-point); 4x memory reduction with <1% accuracy loss across MODEL ARCH 4 (72k params) and MODEL ARCH 8 (52k params).”
- “Full Verilog RTL CNN: parametric conv2d, max-pool, residual/shortcut add (1x1 conv), GAP, dense, softmax in Q7 fixed-point; FSM-controlled with two-cycle ready/valid handshake; validated end-to-end at 84% accuracy (100 CIFAR-10 images, FP32 and Q1.7).”
- “Systolic array GEMM and Conv2D: 9-PE CSA-MBE MAC array with Booth multiplier and CSA tree reduction, 3-stage pipeline; benchmarked CSA/Kogge-Stone/RCA adders and MBE/Booth/Baugh-Wooley multipliers on Sky130 RTL2GDS (Yosys/OpenSTA) based on fmax, power and area; GDS and layouts generated.”
- “Streaming Zynq-7000 architecture with AMBA AXI: AXI4-Lite for runtime weight/bias loading from DDR, AXI-Stream for pixel ingestion with FIFO decoupling, AXI-Lite for control; first convolution layer validated against Python golden model (+-1 LSB rounding deviation).”
- “SW baselines on PYNQ ARM Cortex-A9: NumPy inference (~21s/image FP32, ~30s/image Q1.7); keras2c evaluated across baseline, loop-pragma, and graph-fused variants (residual fusion, tensor materialization reduction) at O0-Ofast; best ~361ms/image.”
- “hls4ml (Vivado HLS, ap_fixed<16,6>, ReuseFactor=32, Resource strategy) and Vitis HLS (ap_fixed<16,8>, AXI-MM + AXI-Lite) explored for HLS-based acceleration.”
- “Brevitas QAT (4-bit weights/activations, 8-bit input) + FINN 17-stage dataflow compilation targeting Zybo Z7-10 (xc7z010clg400-1); custom board integration, AXI-Stream + AXI-Lite PS-PL; post-synthesis: 11,581 LUT, 14,557 FF, 17 BRAM36K, 3 DSP; bitstream generated.”
- “Vitis HLS kernel on xc7z020: 18,379 LUT (34%), 243 BRAM_18K (86%), 22 DSP (10%), Fmax 136.99 MHz.”
Unified Theme
Across all branches—ImProVe, NeVer, MOVe, CNN acceleration, systolic microarchitecture, CORDIC IP, and FPGA deployment—the consistent focus has been:
- Fixed-point arithmetic design
- Pipelined microarchitectures
- Streaming interfaces (AXI-Stream)
- Hardware–software co-validation
- Quantization vs scaling trade-offs
- Automation of inference workflows
- Exploration of arithmetic-level PPA trade-offs
- Introduction to physical design and formal verification
The work collectively represents iterative exploration of hardware-aware ML acceleration, rather than a single linear product.