
Verilog for Image Processing and Simulation-based Inference Of Neural Networks

NEural NEtwork in VERilog; CIFAR10-CNN
Developed a lightweight CNN [Conv2D×2 + MaxPool]×3 → GAP → Dense(10) for CIFAR-10 Image Classification (32x32RGB) using both IEEE 754 floating-point and Q1.31, Q1.15, Q1.7, and Q1.3 fixed-point arithmetic, achieving 84% accuracy in both implementations (Py ~85% | FP ~84% | Q31 ~84% | Q15 ~84% | Q7 ~82% | Q3 ~65%)
View Project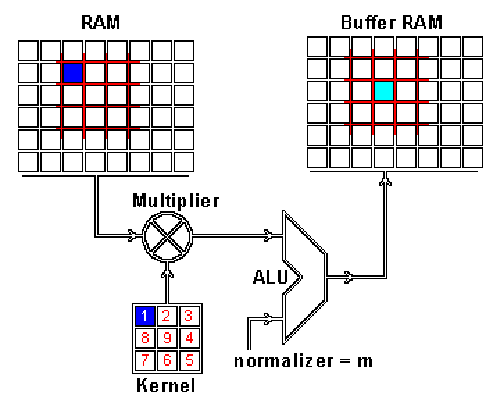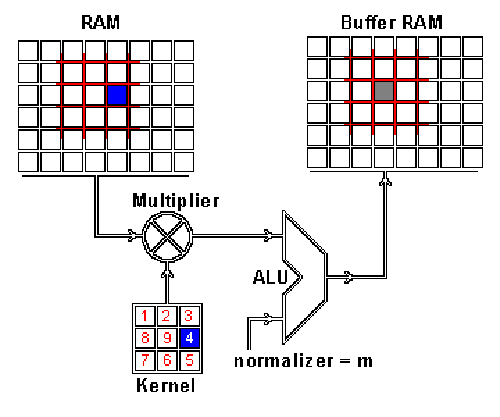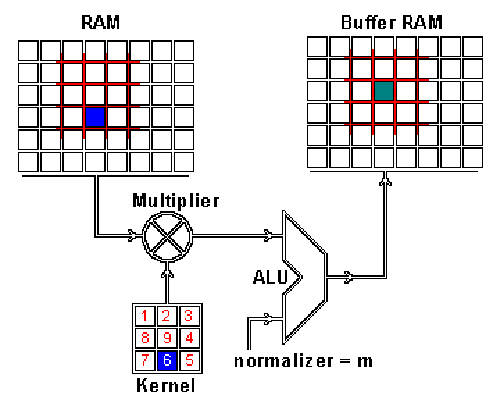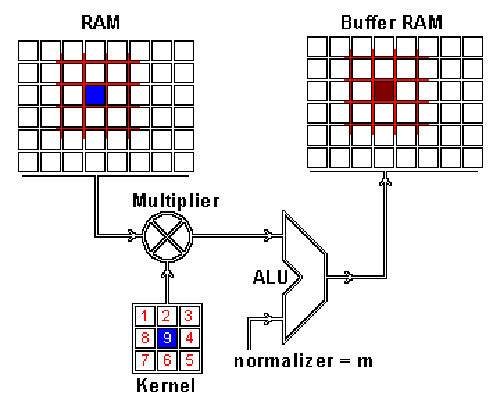
IMage PROcessing using VErilog
ImProVe (IMage PROcessing using VErilog) is a project focused on implementing image processing techniques using Verilog. It involves building image processing logic from the ground up, exploring various algorithms and approaches within HDL
View Project
NEural NEtwork in VERilog; (E)MNIST-MLP
Never (NEural NEtwork in VERilog) implements a neural network in Verilog for better hardware acceleration of image processing tasks
View Project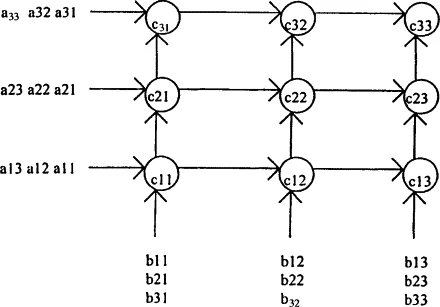
Matrix Multiplier with Systolic Array
Systolic array of MAC PEs with Booth multipliers and carry-save adders, supporting both GEMM and 3×3 CNN convolutions for hardware-accelerated deep learning and linear algebra
View Project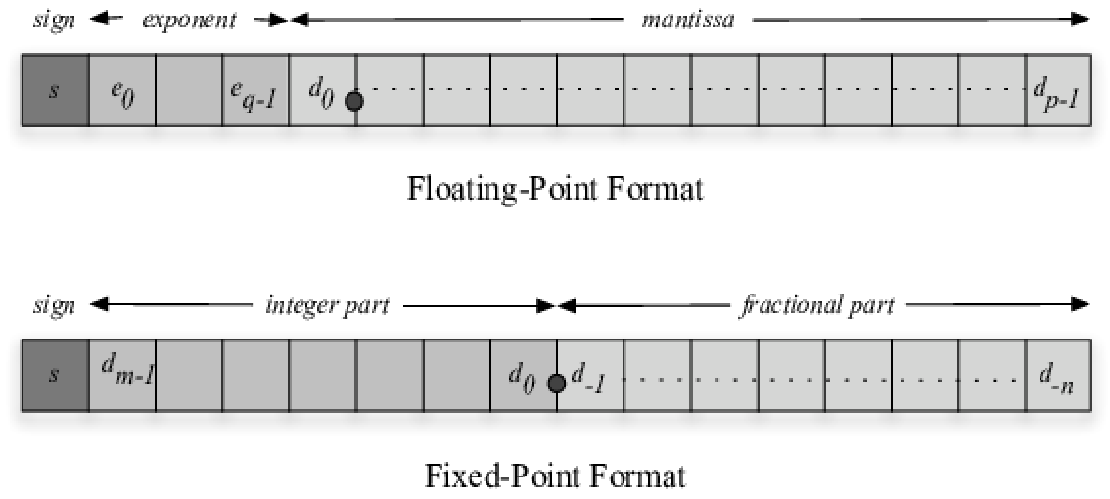
Fixed-Point Conversion Report for EMNIST Neural Network
This report outlines the transition of the EMNIST neural network from floating-point (IEEE754) to fixed-point arithmetic to reduce hardware complexity and improve synthesis compatibility, while aiming to preserve model accuracy
View ProjectNo projects found for the selected tags.
High-Performance Quantized CNN Hardware Accelerator for Lightweight Inference (Verilog) | Link
Design of High-Performance Q1.7 Fixed-Point Quantized CNN Hardware Accelerator with Microarchitecture Optimization of 3-Stage Pipelined Systolic MAC Arrays for Lightweight Inference
" I tried to ImProVe, but NeVer really did — so I MOVe-d on ¯\_(ツ)_/¯ “
Current Project Overview
Duration: Individual, Ongoing
Tools: Verilog (Icarus Verilog, Yosys) | Python (TensorFlow, NumPy) | Scripting (TCL, Perl)
8-bit Quantized CNN Hardware Accelerator: Open-source, Modular, & Optimized for Inference
Verilog | Basic Architecture | Digital Electronics
- Designed a shallow residual-style CNN for CIFAR-10, achieving ~84% accuracy (< 1% loss) with a 52 KB model size (only ~17× 3 KB input). Applied post-training quantization variants including Q1.7 (8-bit signed), optimizing accuracy, model size, and inference efficiency.
- Implemented synthesizable Verilog modules (Testbench Verified) with FSM-based control, 2-cycle handshake, and auto-generated ROMs (14: weights/biases & 3 (RGB): input). Intermediate values stored in registers and computed using systolic array-based MAC units.
- Explored key image-processing techniques including edge detection, noise reduction, filtering, and enhancement. Implemented (E)MNIST classification using MLP, achieving >75% accuracy. Automated inference flow with TCL/Python scripts and manual GUI inputs.
Technical Summary
Designed a fully synthesizable INT8 CNN accelerator (Q1.7 PTQ) for CIFAR-10, optimized for throughput, latency determinism, and precision efficiency. Implemented a 2-cycle ready/valid handshake for all inter-module transactions and FSM-based control sequencing for deterministic pipeline timing. Trained 8 CNNs (TensorFlow, identical augmentation & LR scheduling w/ vanilla Adam optimizer) and performed architecture-level DSE via Pareto analysis, selecting 2 optimal variants including a ResNet-style residual CNN.
PTQ/QAT comparisons were conducted across Q1.31, Q1.15, Q1.7, and Q1.3; Q1.7 PTQ (1-int, 7-frac | 0.0078 step) gave the best accuracy–memory trade-off { Q1.31 ~84% ~210kB | Q1.7 ~83% ~52kB | Q1.3 ~78% ~26kB }, achieving ~84% top-1 accuracy, <1% loss, and ≈52 KB total (≈17×3 KB RGB inputs)
The 3-stage pipelined systolic-array convolution core employs Processing Elements (PEs) built around MAC units composed of 8-bit signed Carry-Save Adders (CSA) and Modified Booth-Encoded (MBE) multipliers, arranged in a 2D grid for high spatial reuse and single-cycle accumulation. All 14 coefficient ROMs and 3 RGB input ROMs were auto-generated via a Python/TCL automation flow handling coefficient quantization, packing, and open-source EDA simulation. Verified bit-accurate correlation between TensorFlow FP32 and RTL fixed-point inference layer-wise; an IEEE-754 single-precision CNN variant validated numeric consistency.
Integrated image-processing modules (edge detection, denoising, filtering, contrast enhancement) form a Verilog-based hardware preprocessing pipeline, feeding an MLP classifier evaluated on the (E)MNIST (52+)10 ByClass datasets. The MLP shares the preprocessing and automation flow, with an additional IEEE-754 64-bit FP variant for precision benchmarking. A Tkinter GUI enables interactive character input, and preprocessing visualization via Matplotlib
High-Speed 3-Stage Pipelined Systolic Array-Based MAC Architectures
Digital Logic Design | Synthesis
- Compared 6 × 8-bit adders/multipliers for systolic-array MACs using PPA metrics (latency / throughput / area, sky130 nm PDK) and analyzed trade-offs.
- Final design uses Carry-Save Adder (CSA) and Modified Booth Encoder (MBE) multiplier for 3×3 convolution and GEMM operations with 3-stage pipelined systolic arrays, verified for 0 / same padding modes.
- Pipeline Stages: sampling image → truncating & flipping → MAC accumulation.
Technical Summary
Benchmarked six 8-bit signed adder and multiplier architectures for systolic-array MACs targeting CNN/GEMM workloads using a fully open-source ASIC flow (Yosys + OpenROAD/OpenLane) on the Google-SkyWater 130nm PDK (Sky130HS PDK @25°C_1.8V). Evaluated PPA (Power, Performance, Area) and latency/throughput/area metrics under a constant synthesis and layout environment with fixed constraints and floorplan parameters (FP_CORE_UTIL = 30 %, PL_TARGET_DENSITY = 0.36, 10 ns clock, CTS/LVS/DRC/Antenna enabled)
Adders:
- CSA – 5.07 ns CP, 197 MHz Fmax, 2.52 k µm² core, 0.083 mW (best speed/resource trade-off)
- Kogge–Stone – 6.21 ns, 161 MHz, 3.69 k µm² (area-heavy)
- RCA – 7.14 ns, 140 MHz, 1.13 k µm², 0.032 mW (most power/area-efficient)
Multipliers:
- MBE – 8.84 ns, 113 MHz, 9.6 k µm², 0.379 mW (best energy/area efficiency = 3.35 × 10³ pJ/op, 8.64 × 10³ ops/s/µm²)
- Baugh–Wooley – 8.63 ns, 115.9 MHz (fastest)
- Booth (Radix-2) – 12.5 ns, 80 MHz (highest area/power)
Final MAC integrates an 8-bit signed CSA adder and 8-bit signed MBE multiplier in a 3×3 convolution/GEMM core using a 3-stage pipelined systolic array (sampling → truncation/flipping → MAC accumulation). Verified via RTL testbench and post-synthesis timing across zero/same-padding modes. Automated GDS/DEF generation and PPA reporting for all architectures ensured fully reproducible, environment-consistent results
Comparative study (Small Scale Ops) :
CSA-MBE pair Systolic Array Conv vs Naïve Conv (3x3 Kernel on 5x5 Image @CLK_PERIOD_20_ns)
- Latency ↓ 66.3% Throughput ↑ 196.6% Speed ↑ 196.6% Area ↓ 67.8% Power ↓ 82.2%
Single MAC re-use vs Systolic 4-PE Grid (2x2 matrix multiplication)
- Latency ↓ 0.9% Throughput ≈ same Speed ≈ same Area ≈ same Power ↓ 15% Energy/op ↓ 14.6%
Single MAC re-use vs Systolic 9-PE Grid (3x3 matrix multiplication)
- Latency ↓ 1% Throughput ≈ same Speed ≈ same Area ≈ same Power ↓ 44.6% Energy/op ↓ 44%
Repositories

ViSiON – Verilog for Image Processing and Simulation-based Inference Of Neural Networks
This repo includes all related projects as submodules in one place
 |  |
ImProVe – IMage PROcessing using VErilog: A collection of image processing algorithms implemented in Verilog, including geometric transformations, color space conversions, and other foundational operations.
NeVer – NEural NEtwork on VERilog: A hardware-implemented MLP in Verilog for character recognition on (E)MNIST, alongside a lightweight CNN for CIFAR-10 image classification
MOVe – Math Ops in VErilog
 |  |
 |  |
CORDIC Algorithm – Implements Coordinate Rotation Digital Computer (CORDIC) algorithms in Verilog for efficient hardware-based calculation of sine, cosine, tangent, square root, magnitude, and more.
Systolic Array Matrix Multiplication – Verilog implementation of matrix multiplication using systolic arrays to enable parallel computation and hardware-level performance optimization. Each processing element leverages a Multiply-Accumulate (MAC) unit for core operations.
Hardware Multiply-Accumulate Unit – Implements and compares 8-bit multipliers and 8-bit adders in synthesizable Verilog, analyzing their area, timing, and power characteristics in MAC datapath architectures.
Posit Arithmetic (Python) – Currently using fixed-point arithmetic; considering Posit as an alternative to IEEE 754 for better precision and dynamic range. Still working through the trade-off.
Storage and Buffer Modules
RAM1KB – A 1KB (1024 x 8-bit) memory module in Verilog with write-once locking for even addresses. Includes a randomized testbench. Also forms the base for a ROM3KB variant to store 32×32 RGB CIFAR-10 image data.
FIFO Buffer – Not started. Planned as a synchronous FIFO with fixed depth, single clock domain, and standard full/empty flag logic.