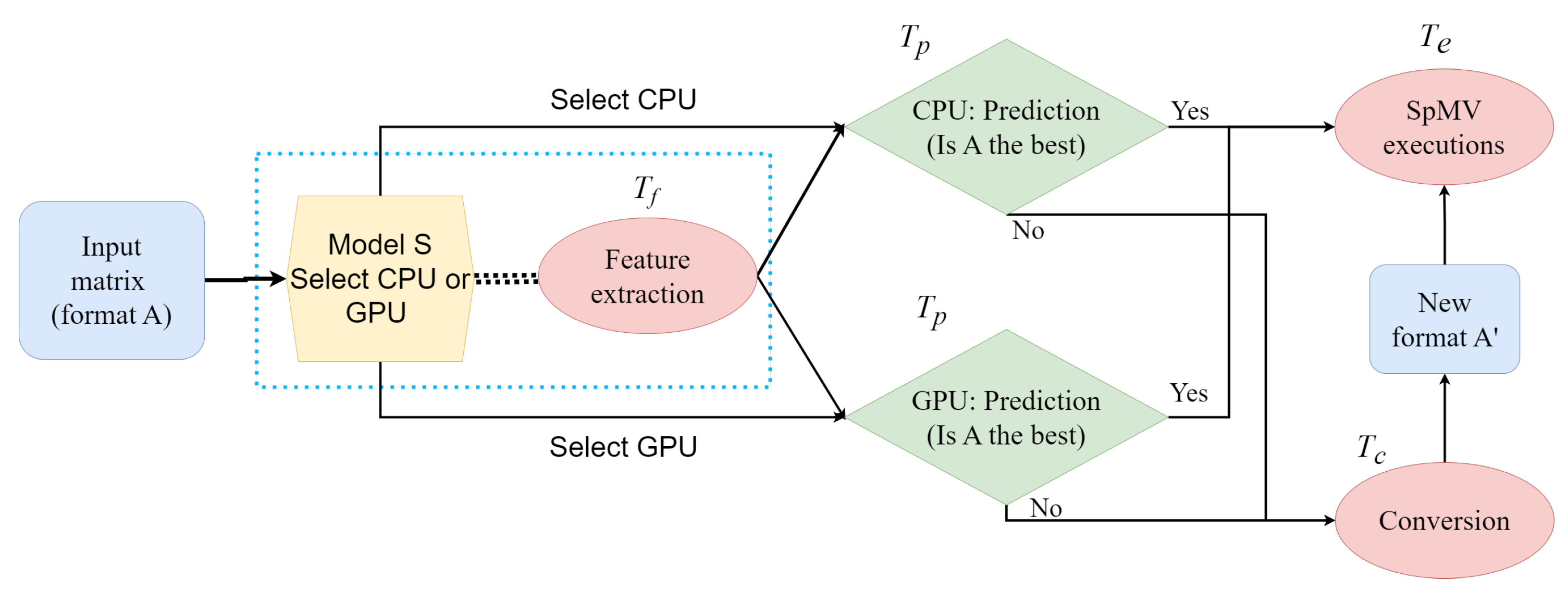
CSR SpMV Benchmark and Memory Roofline Analysis
Current Status:
Heterogeneous CPU–GPU SpMV with Roofline Analysis | CUDA, OpenMP, Performance Modeling
- Built CSR-based Sparse Matrix–Vector (SpMV) engine with OpenMP CPU and CUDA GPU kernels; evaluated across structured, power-law, and mixed sparsity distributions (up to 54M+ nonzeros).
- Designed warp-cooperative kernel using __shfl_down_sync to mitigate load imbalance; improved effective bandwidth from 128 GB/s → 336 GB/s (2.6×) on irregular matrices, approaching Tesla T4 DRAM peak (320 GB/s).
- Achieved ~42 GFLOP/s at OI=0.125, validating memory-bound behavior via full Roofline model (GPU DRAM, PCIe, compute ceilings).
- Measured PCIe transfer bandwidth (pageable: 6.7 GB/s; pinned: 13.1 GB/s) and quantified heterogeneous bottlenecks across CPU (~15 GB/s), PCIe, and GPU memory hierarchy."