Dual-Issue In-Order Superscalar 16-bit RISC Processor
| Repository | Mummanajagadeesh/risc16-dual-superscalar-core |
|---|---|
| Start Date | Sep 2025 |
Summary
| Item | Description |
|---|---|
| Issue Width | Dual (2 instructions per cycle) |
| Execution Model | In-order issue, execution, and retirement |
| Pipeline | IF → ID → EX → MEM → WB (per lane) |
| Register File | 4R / 2W multi-ported |
| Memory | Unified, multi-port |
| Hazard Handling | Full inter- and intra-lane detection |
| Forwarding | Cross-lane and cross-stage |
Superscalar Processor (RiSC-16 Variant)
Dual-Issue In-Order Superscalar 16-bit RISC Processor with Multi-Port Memory, 5-Stage Pipeline, Full Hazard Detection, Cross-Lane Forwarding, and Dual Commit Logic
This project implements a complete *2-way in-order superscalar processor- based on a compact 16-bit RISC architecture. The design dispatches up to two instructions per cycle while strictly preserving architectural ordering.
The processor integrates:
- Parallel decode and execution lanes
- Multi-way dependency checking
- Cross-lane forwarding network
- Multi-ported register file
- Unified memory subsystem
- Dual write-back commit logic
The entire system is written in synthesizable Verilog.
Architectural Block Diagram
+------------------+
| Memory System |
| (3-Port ARAM) |
+------------------+
^ ^
| |
+--------------+ +-----------------+
| |
+---------------+ +---------------+ +---------------+
| IF Stage 0 | | IF Stage 1 | | PC Logic |
+---------------+ +---------------+ +---------------+
| |
v v
+---------------+ +---------------+
| IF/ID Pipe | | IF/ID Pipe |
| Register 0 | | Register 1 |
+---------------+ +---------------+
| |
v v
+---------------+ +---------------+
| ID/EX Pipe | | ID/EX Pipe |
| Register 0 | | Register 1 |
+---------------+ +---------------+
| |
v v
+---------------+ +---------------+
| EX/MEM Pipe | | EX/MEM Pipe |
| Register 0 | | Register 1 |
+---------------+ +---------------+
| |
v v
+---------------+ +---------------+
| MEM/WB Pipe | | MEM/WB Pipe |
| Register 0 | | Register 1 |
+---------------+ +---------------+
| |
+-----------+-----------+
v
Register File
Execution Model
The processor fetches 32 bits per cycle (two 16-bit instructions). Both lanes share identical pipeline depth but operate on independent datapaths where required.
Ordering guarantees:
- In-order issue
- In-order execution (pipeline-overlapped)
- In-order retirement
Superscalar capability is enabled by:
- Simultaneous dual decode
- Independent ALUs
- Multi-port register access
- Dual write-back ports
- Explicit inter-lane dependency arbitration
Superscalar Issue Logic
Lane 1 issues only when safe. The control logic enforces:
RAW Hazards (Inter-Lane)
If: \[ rd_0 = rs_1 ;; \text{or} ;; rd_0 = rt_1 \] lane 1 is suppressed.
WAW Hazards
If: \[ rd_0 = rd_1 \] lane 1 is cancelled.
Structural Restrictions
- Only one memory operation per cycle
- Branch instructions are single-issued
- Functional unit conflicts block pairing
Branch Pairing Policy
- Branches cannot pair
- Taken branches squash younger instructions
- PC redirection restarts fetch
Pipeline Organization
Parallelized classical RISC structure:
\[ IF \rightarrow ID0/ID1 \rightarrow EX0/EX1 \rightarrow MEM0/MEM1 \rightarrow WB0/WB1 \]
Each lane contains:
- Independent pipeline registers
- Independent ALU
- Independent bypass selection
- Dedicated write-back port
Shared structures:
- Instruction fetch logic
- Unified data memory
- Multi-ported register file
Forwarding Network
Forwarding spans:
- EX/MEM → ID/EX (both lanes)
- MEM/WB → ID/EX (both lanes)
- Lane 0 → Lane 1 (same cycle)
- Lane 1 → Lane 0 (ordering-checked cases)
Selection logic is based on:
- Register index matching
- Destination validity
- PC temporal ordering
- Opcode classification
This enables correct resolution of most RAW hazards without stalling.
Register File Architecture
Tri-ported logical structure:
- 4 read ports (2 per lane)
- 2 write ports (1 per lane)
- Lane 0 commit priority
r0hardwired to zero
Commit policy guarantees strict in-order retirement.
Memory Subsystem
Unified memory design:
- Two combinational instruction read ports
- One effective data memory operation per cycle
- Dual-issue logic prevents conflicting load/store pairing
This eliminates MEM-stage structural hazards.
Example Run — Summation Benchmark
Program computes:
\[ 0 + 1 + 2 + \dots + 10 = 55 \]
Assembly Program
ADDI r1, r0, 0
ADDI r1, r1, 1
ADDI r1, r1, 2
ADDI r1, r1, 3
ADDI r1, r1, 4
ADDI r1, r1, 5
ADDI r1, r1, 6
ADDI r1, r1, 7
ADDI r1, r1, 8
ADDI r1, r1, 9
ADDI r1, r1, 10
HALT
Machine Code
2080
2481
2482
2483
2484
2485
2486
2487
2488
2489
248a
e071
Final expected result:
\[ r1 = 0037_{16} = 55_{10} \]
Superscalar Waveform
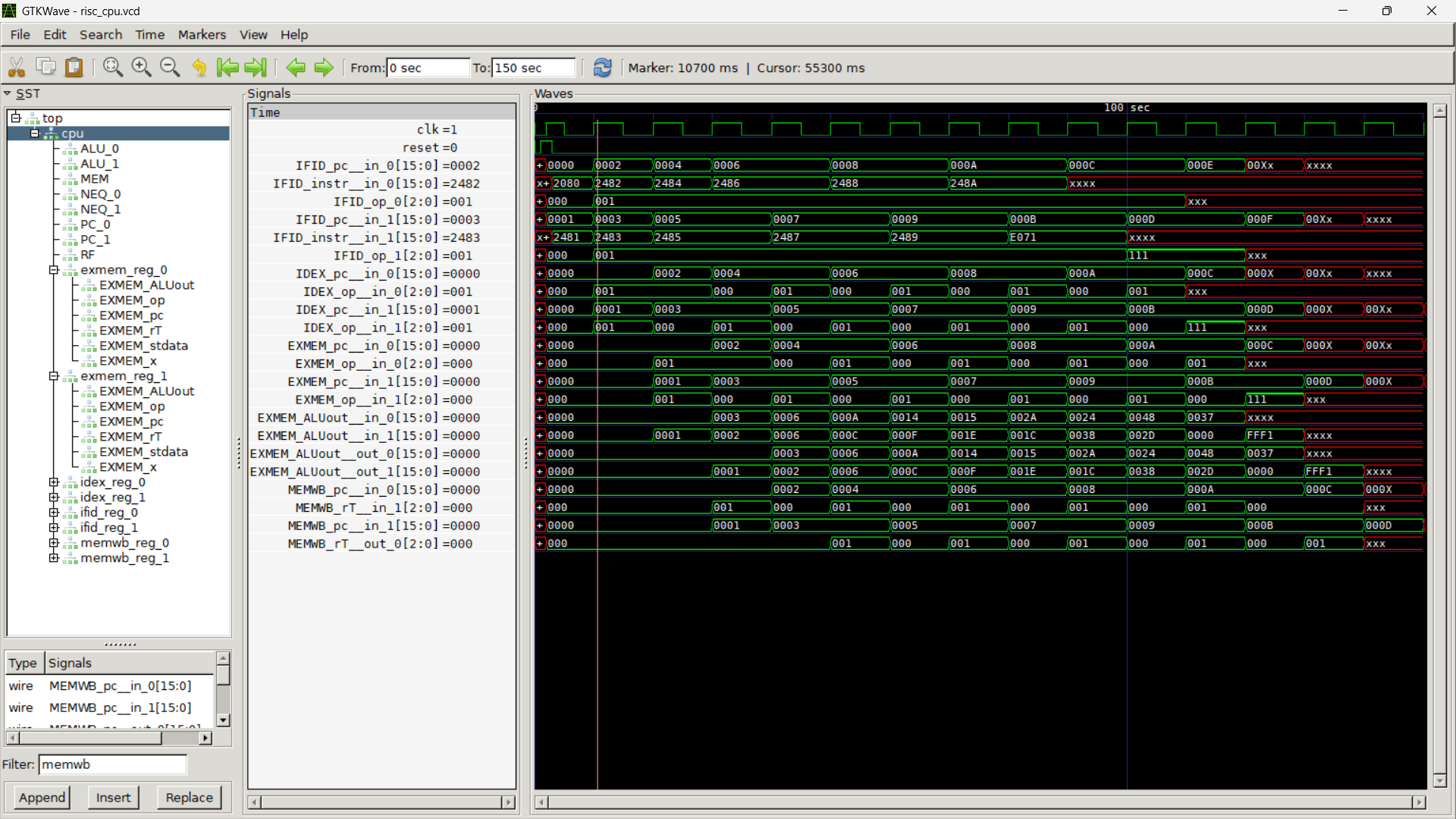
Observed behavior:
-
Dual fetch visible in IF stage
-
Lane 1 suppressed due to RAW on
r1 -
EXMEM_ALUOut_0shows cumulative sums:0000 → 0001 → 0003 → 0006 → 000A → ... → 0037 -
Correct in-order write-back
-
HALT cleanly drains pipeline
Although dual-issue capable, this benchmark serializes due to true dependencies.
Terminal Output
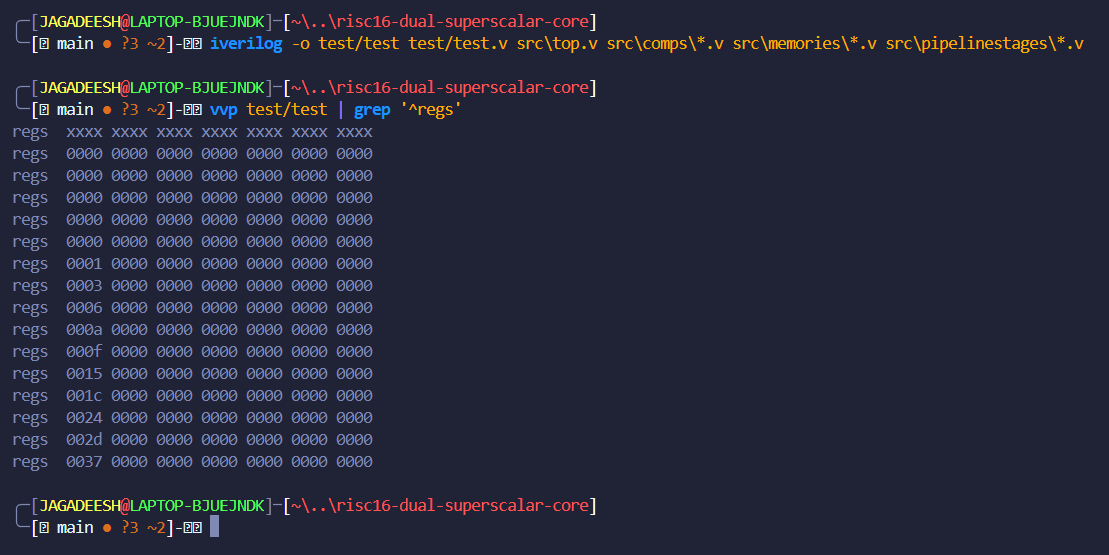
Final register dump:
regs .... 0037 0000 0000 0000
Confirms:
\[ 0037_{16} = 55_{10} \]
Waveform and terminal output are fully consistent.
Current Limitations
- Partial ISA implementation
- No speculation
- No branch prediction
- No dynamic scheduling
- Only basic load-use stalling
Future Evolution Toward Out-of-Order
To transform this design into a modern dynamic superscalar core:
Register Renaming
Eliminate WAR/WAW hazards via physical register mapping.
Reservation Stations
Buffer instructions until operands are ready.
Common Data Bus (CDB)
Broadcast execution results.
Reorder Buffer (ROB)
Enable out-of-order execution with in-order retirement.
Tomasulo-Style Engine
Provide:
- Dynamic scheduling
- Automatic wakeup/select
- Speculative execution
- Higher instruction-level parallelism
Directory Structure
src/
top.v
pipelinestages/
comps/
memories/
assembly/
test/
test.v