L2 Tile Cache — Cached Tiled GEMM
The cache implemented here is a direct-mapped on-chip tile cache — it has tag RAM, valid bits, combinational hit detection, and a DMA fill path on miss. Calling it “L2” is a convenience label based on where it sits structurally: the PE accumulators act as L1 (data lives there during computation), and this cache sits one level above between the ping-pong SRAMs and DRAM. But the RTL itself has no knowledge of any hierarchy — it is just an SRAM with cache semantics. Whether it is L1, L2, or a scratchpad in your actual system depends entirely on what else surrounds it.
L2 Tile Cache Layer
This document covers the four new modules added on top of the existing ping-pong wrapper.
The ping-pong wrapper (gemm_wrapper, gemm_ctrl, sram_bank, ping_pong_buf,
output_buf) is treated as a black box here — see the other doc for that layer.
The Problem Being Solved
The ping-pong wrapper decouples loading from computing — the host DMA fills the shadow bank while the array computes from the active bank. But it still requires the host to supply fresh tile data for every tile, every time, directly from DRAM. For workloads where the same weights (A matrix) are reused across many output tiles — the dominant pattern in Conv2d — this means redundant DRAM traffic. The same filter slice gets fetched over and over.
The L2 tile cache intercepts every tile load request. If the tile is already resident on-chip, it streams directly from cache SRAM without touching DRAM. Only a genuine miss triggers a DMA fetch. The array never sees the difference — the shadow bank gets filled either way before FLIP_INIT.
Architecture
DRAM
│
dma_a_req/ack/we/data dma_b_req/ack/we/data
│ │
┌─────────┴──────────────────────────┴─────────┐
│ │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ tile_cache (A) │ │ tile_cache (B) │ │
│ │ tag+valid SRAM │ │ tag+valid SRAM │ │
│ └────────┬────────┘ └────────┬────────┘ │
│ │ hit/miss │ hit/miss │
│ ┌────────┴────────┐ ┌────────┴────────┐ │
│ │ cache_ctrl (A) │ │ cache_ctrl (B) │ │
│ │ LOOKUP/FILL │ │ LOOKUP/FILL │ │
│ └────────┬────────┘ └────────┴────────┘ │
│ │ pp_wr_* │ pp_wr_* │
│ ▼ ▼ │
│ ping_pong_buf(A) ping_pong_buf(B) │
│ │ │ │
│ └──────┬───────────┘ │
│ ▼ │
│ gemm (unchanged) │
│ │ c_out_w │
│ output_buf │
│ │ │
│ gemm_ctrl_cached (FSM) │
│ ┌──────────────────────────────┐ │
│ │ CACHE_REQ → CACHE_WAIT → │ │
│ │ FLIP_INIT → PRELOAD → │ │
│ │ RUNNING → DRAIN → │ │
│ │ CAPTURE_WAIT → CAPTURE → │ │
│ │ WRITEBACK → (loop or IDLE) │ │
│ └──────────────────────────────┘ │
└───────────────────────────────────────────────┘
New Module Reference
tile_cache
Direct-mapped set-associative SRAM cache. One instance per operand (A and B).
Parameters: NUM_SETS, TILE_WORDS (=K), WORD_WIDTH (=max(8*M,8*N)), TAG_WIDTH
Data SRAM: NUM_SETS × TILE_WORDS × WORD_WIDTH bits, indexed as
mem[set * TILE_WORDS + word_addr]. Holds one full operand tile per set — K words,
each word being one column-slice of A (8·M bits) or row-slice of B (8·N bits).
Tag RAM: NUM_SETS × TAG_WIDTH register array. Tags survive rst (only valid_r
is reset, not the tag RAM data itself).
Valid bits: NUM_SETS × 1 register array, reset to 0 on rst.
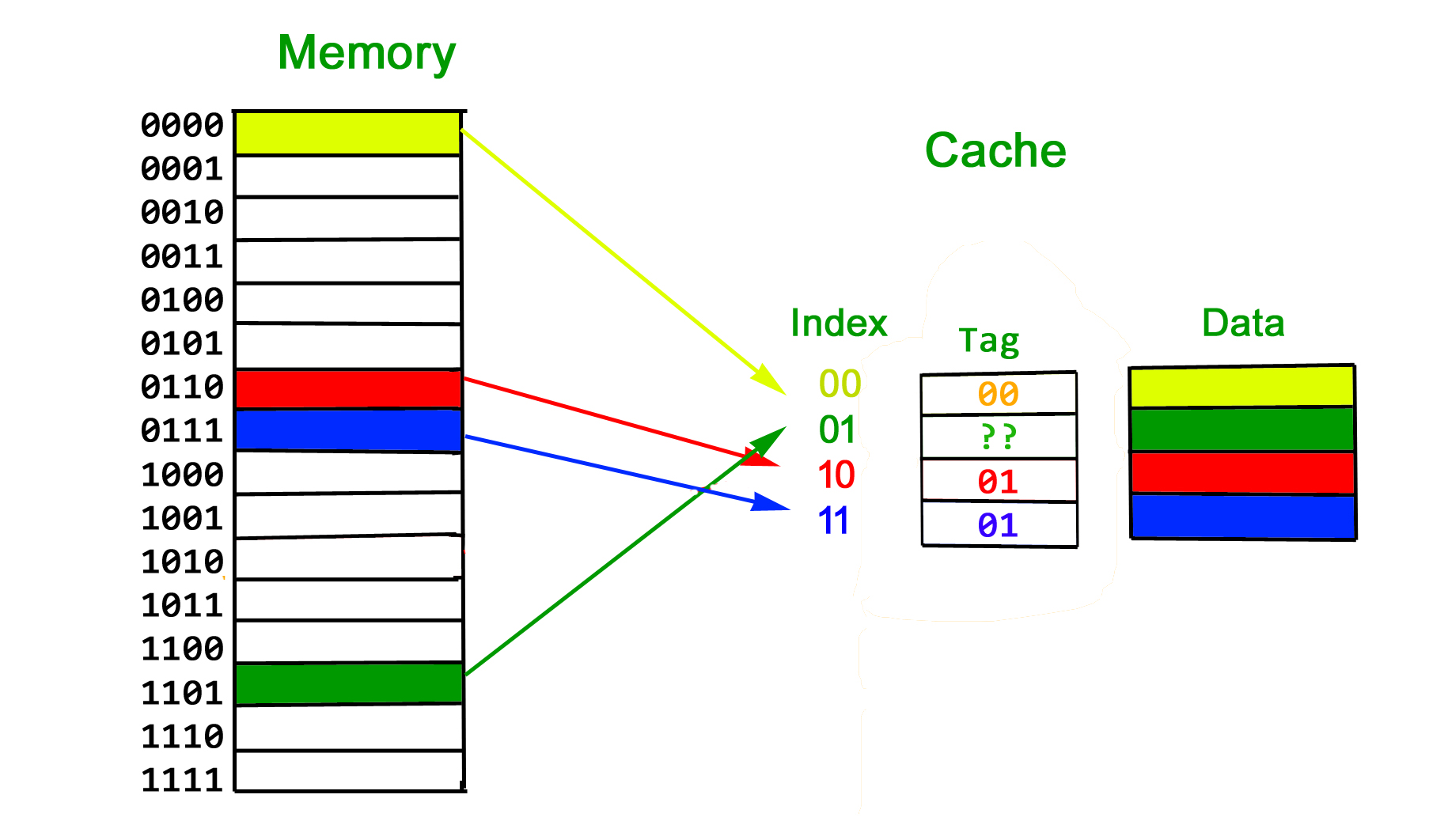
Set index (direct-map): set = lu_tag[SET_W-1:0] — the low log2(NUM_SETS) bits
of the tag. Tags that differ only in higher bits alias to the same set and evict each
other. Tag 0 and tag 4 both map to set 0 with NUM_SETS=4.
Hit detection (combinational):
lu_set = lu_tag[SET_W-1:0]
lu_hit = lu_valid && valid_r[lu_set] && (tag_ram[lu_set] == lu_tag)
This fires in the same cycle as lu_valid — no extra latency for the tag compare.
Fill interface:
fill_we, fill_set, fill_addr, fill_data — write one word per cycle
fill_tag, fill_done — commit tag and set valid_r on completion
Hit/miss counters: 32-bit saturating counters incremented on every lu_valid pulse.
cache_ctrl
One instance per operand. Mediates between the tile request from gemm_ctrl_cached,
the tile_cache lookup/fill ports, the DMA interface, and the ping-pong shadow bank
write port.
FSM
┌────────┐ req_valid ┌─────────┐
│ IDLE │────────────►│ LOOKUP │
└────────┘ └────┬────┘
hit? │ miss?
┌─────────┴──────────┐
▼ ▼
┌────────────┐ ┌──────────┐
│ HIT_STREAM │ │ MISS_REQ │
│ (K cycles) │ │ wait ack │
└─────┬──────┘ └────┬─────┘
│ ▼
│ ┌───────────┐
│ │ MISS_FILL │
│ │ K words │
│ └─────┬─────┘
└──────┬───────────┘
▼
┌──────┐
│ DONE │ → pulse load_done → IDLE
└──────┘
IDLE: waits for req_valid. When it fires, latches req_tag into saved_tag at
that same posedge (critical — req_tag is only driven in ST_CACHE_REQ by the ctrl
and is gone by the time cache_ctrl reaches LOOKUP).
LOOKUP (1 cycle): drives lu_valid=1, lu_tag=saved_tag to tile_cache. Hit or
miss is combinationally available by the end of this cycle.
HIT_STREAM (K+1 cycles): reads K words from cache SRAM into the ping-pong shadow
bank. The 1-cycle SRAM read latency means rd_en runs ahead of pp_wr_en by one
cycle — pp_wr_addr lags rd_addr by 1, and the write fires when rd_data is valid.
MISS_REQ: asserts dma_req and dma_tile_id, holds until dma_ack fires.
MISS_FILL (K cycles): receives DMA words via dma_we/addr/data. Each word goes
simultaneously to:
tile_cachefill port → writes into cache SRAMpp_wr_*→ writes directly into ping-pong shadow bank
This refill-and-use path means the shadow bank is filled in parallel with the cache, adding zero extra latency compared to a direct DMA-to-SRAM path.
DONE (1 cycle): pulses fill_done to tile_cache (commits tag and sets valid_r),
and pulses load_done to gemm_ctrl_cached.
gemm_ctrl_cached
Extended sequencer FSM. Replaces gemm_ctrl for the cached system. Adds two states
(CACHE_REQ, CACHE_WAIT) at the front of each tile’s pipeline and connects to
cache_ctrl via the tile request interface.
FSM
┌────────┐ start ┌───────────┐ ┌────────────┐
│ IDLE │─────────►│ CACHE_REQ │────────►│ CACHE_WAIT │
└────────┘ └───────────┘ └─────┬──────┘
▲ │ a_load_done
│ tile_cnt==NUM_TILES-1 │ & b_load_done
│ ▼
┌───────────┐ ┌─────────────┐ ┌───────────┐
│ WRITEBACK │◄────────│ CAPTURE │ │ FLIP_INIT │
└───────────┘ └─────────────┘ └─────┬─────┘
│ else ▲ ▼
▼ ┌────┴──────┐ ┌──────────┐
┌───────────┐ │CAPTURE_WT │ │ PRELOAD │
│ CACHE_REQ │◄──────────│ │ └─────┬────┘
└───────────┘ └────────── ┘ ▼
┌─────────┐
│ RUNNING │
└────┬────┘
│ k_cnt==K-1
▼
┌─────────┐
│ DRAIN │
└─────────┘
CACHE_REQ (1 cycle): drives a_req_valid=1, b_req_valid=1 with tags derived from
tile_cnt — A tag = {1'b0, tile_cnt[6:0]}, B tag = {1'b1, tile_cnt[6:0]}. These
fire for exactly 1 cycle, then cache_ctrl has registered saved_tag and REQ goes low.
CACHE_WAIT: holds until a_load_done & b_load_done both asserted. Duration is:
- Hit path:
1 (LOOKUP) + K+1 (HIT_STREAM) + 1 (DONE)= K+3 cycles = 6 cycles for K=3 - Miss path:
1 (LOOKUP) + 1 (MISS_REQ) + DMA_LATENCY + K (MISS_FILL) + 1 (DONE)= DMA_LATENCY+K+3 cycles
FLIP_INIT: fires flip_en to both ping-pong buffers. The shadow bank (now fully
written by cache_ctrl) becomes the active bank. Gemm reads from it immediately in
PRELOAD/RUNNING.
Everything from FLIP_INIT onward is identical to gemm_ctrl.
Tile tag generation:
tile-0: a_req_tag = 8'h00 b_req_tag = 8'h80
tile-1: a_req_tag = 8'h01 b_req_tag = 8'h81
tile-N: a_req_tag = 8'h0N b_req_tag = 8'h8N
The upper bit distinguishes A tiles from B tiles in the unified cache tag space.
gemm_cached_wrapper
Top-level integration. Wires tile_cache × 2, cache_ctrl × 2, ping_pong_buf × 2,
gemm, output_buf, and gemm_ctrl_cached together. No logic — only port connections
and two pipeline registers.
Width normalisation: A words are 8*M bits, B words are 8*N bits. Both tile caches
use WORD_WIDTH = max(8*M, 8*N). Narrower operand data is zero-padded before the cache
write and stripped on read. Done via intermediate wires dma_a_data_w / dma_b_data_w.
out_we_r delay: same as in the ping-pong wrapper — out_we, out_acc, out_flush
are delayed 1 cycle to align with gemm.c_out settling after done.
Latency Analysis
Cold miss (first access to a tile)
CACHE_REQ (1)
CACHE_WAIT (LOOKUP=1 + MISS_REQ=1 + DMA_LATENCY + MISS_FILL=K + DONE=1)
FLIP_INIT (1)
PRELOAD (1)
RUNNING (K)
DRAIN (MIN_GAP)
CAPTURE_WAIT + CAPTURE (2)
WRITEBACK (1)
out_we_r delay (1)
─────────────────────────────────────────────────────────────
Total ≈ DMA_LATENCY + 2*K + MIN_GAP + 10 cycles
For M=N=K=3, MIN_GAP=4, DMA_LATENCY=3: 3 + 6 + 4 + 10 = 23 cycles minimum.
Measured: 26 cycles (a few extra CAPTURE_WAIT cycles waiting for done).
Cache hit (tile already resident)
CACHE_REQ (1)
CACHE_WAIT (LOOKUP=1 + HIT_STREAM=K+1 + DONE=1)
FLIP_INIT (1)
PRELOAD (1)
RUNNING (K)
DRAIN (MIN_GAP)
CAPTURE_WAIT + CAPTURE (2)
WRITEBACK (1)
out_we_r delay (1)
─────────────────────────────────────────────────────────────
Total ≈ 2*K + MIN_GAP + 10 cycles
For M=N=K=3: 6 + 4 + 10 = 20 cycles minimum. Measured: 22 cycles.
Cycles saved per hit
Cold - Hit = DMA_LATENCY + (MISS_FILL - HIT_STREAM) = DMA_LATENCY + (K - (K+1)) + 1
= DMA_LATENCY cycles saved
Measured saving: 4 cycles (DMA_LATENCY=3 + 1 extra FSM cycle). Every cache hit
eliminates one DMA round-trip, hiding DMA_LATENCY cycles of memory latency.
Throughput with cache
Miss path tile period: DMA_LATENCY + K_fill + T_tile + FSM_overhead
Hit path tile period: K_stream + T_tile + FSM_overhead
Cold: 99 cycles / 4 tiles = 24.75 cycles/tile Warm: 83 cycles / 4 tiles = 20.75 cycles/tile
Hit-Rate Mathematics
With NUM_SETS sets and a working set of W unique tiles where W ≤ NUM_SETS
(no eviction), repeated over N passes:
Total requests = W × N
Cold misses = W (always, one per unique tile on first access)
Hits = W × (N-1)
Hit-rate = (N-1) / N
| Passes | Hit-rate |
|---|---|
| 2 | 50.0% |
| 4 | 75.0% |
| 8 | 87.5% |
| 16 | 93.75% |
| 32 | 96.875% |
| ∞ | 100% |
For Conv2d: the filter (A) is typically reused across all output spatial positions. If the filter fits in cache, A hit-rate approaches 100% after warmup. B (input patches) vary per output position and may miss every time unless the spatial reuse pattern fits.
Eviction: with W > NUM_SETS, tags that share the same set (tag % NUM_SETS equal)
evict each other. Tags {0,4,8,...} all map to set 0. Running tiles 0-7 with
NUM_SETS=4 causes tiles 4,5,6,7 to evict tiles 0,1,2,3. Re-accessing tiles 0-3
afterwards incurs misses again.
Challenges and Fixes
1. Tag latched in wrong state — false cache hits on all tiles 1+
Problem: cache_ctrl needed to look up the tile tag in ST_LOOKUP, but req_tag
from gemm_ctrl_cached is only driven during ST_CACHE_REQ (one cycle before LOOKUP).
By the time the cache_ctrl was in LOOKUP, req_tag had returned to zero. The lookup
always compared against tag 0 — which after tile-0 was resident — giving a spurious hit
on every subsequent tile regardless of its actual tag.
Root cause: the original code did saved_tag <= lu_tag in LOOKUP, where
lu_tag = req_tag — but req_tag was already gone.
Fix: latch in IDLE when req_valid=1 (the only cycle req_tag is valid):
ST_IDLE: if (req_valid) saved_tag <= req_tag;
// Then in LOOKUP:
lu_tag = saved_tag; // not req_tag
2. fill_data port double-driven — X propagation into SRAM
Problem: cache_ctrl has an output port fill_data that drives tile_cache’s
fill input. In the wrapper, this was accidentally connected to dma_a_data_w (a wire
also driven by an assign statement from the DMA input). Two drivers on the same wire
in Verilog produces X — which propagated into the cache SRAM and rendered every value
read from it as X.
Fix: route through the intermediate wire a_fill_data_w correctly:
// WRONG: .fill_data(dma_a_data_w) ← double-drives the wire
// RIGHT: .fill_data(a_fill_data_w) ← cache_ctrl drives this, tile_cache reads it
3. FSM ordering: FLIP_INIT before fill → gemm reads zeroes
Problem: original design issued flip_en in FLIP_INIT before cache_ctrl had
finished filling the shadow bank. After the flip, the newly-active bank was the old
shadow (not yet written) and contained stale zeros. Gemm computed C = 0.
Fix: restructure per-tile sequence to fill first, flip second:
OLD: FLIP_INIT → CACHE_REQ → CACHE_WAIT (fill) → PRELOAD → RUNNING
NEW: CACHE_REQ → CACHE_WAIT (fill completes) → FLIP_INIT → PRELOAD → RUNNING
The shadow bank is guaranteed fully written before it becomes the active bank.
4. HIT_STREAM pp_wr_addr part-select on expression — syntax error
Problem: pp_wr_addr = (word_cnt - 1)[WORD_W-1:0] is illegal Verilog — part-selects
cannot be applied to expressions, only to named signals.
Fix: rewrite as an arithmetic expression:
pp_wr_addr = word_cnt[WORD_W-1:0] - 1;
5. Multi-tile FSM stall — CACHE_WAIT entered without prior request
Problem: after tile-0 WRITEBACK, the FSM went to CACHE_WAIT for tile-1 but no
cache_ctrl request had been issued (the original design tried to prefetch during DRAIN
by re-arming req_issued, but the re-arming and next-state condition both depended on
req_issued in the same cycle — the registered update was invisible to the combinational
next-state logic). cache_ctrl stayed IDLE, load_done never fired, CACHE_WAIT spun
forever.
Fix: remove prefetch entirely. Go directly WRITEBACK→CACHE_REQ for the next tile. Sequential fill-then-compute with no overlap. Simpler and correct. Prefetch overlap is future work.
6. T2 cache hit actually a miss — working set evicted between runs
Problem in testbench: with NUM_TILES=8, tile-0 (tag=0, set=0) was evicted by
tile-4 (also set=0) during the same 8-tile run. The T2 “repeat” test fired after the
8-tile run, but tag=0 was no longer resident. So T2 always measured a cold miss (26
cycles) instead of a hit (22 cycles).
Fix: change NUM_TILES=4 so tiles 0-3 fill sets 0-3 with no aliasing. Tag=0 in
set=0 survives the entire 4-tile run. T2 immediately after T1 (no rst between them,
valid_r intact) correctly gets a cache hit.
7. T3/T4 pass-2 showing same speed as pass-1 — hits not faster
Problem: measured 99 cycles for both cold and warm passes — contradicting the hit
path being 4 cycles faster per tile. Root cause: n_captured was not reset between
pass-1 and pass-2, so wait_n_tiles(4) returned immediately (already had 4 captured
from pass-1) and the pass-2 timing measurement was garbage.
Fix: add n_captured=0 before each pass. Warm pass correctly shows 83 cycles vs
cold 99 cycles — 16 cycles total saved across 4 tiles = 4 cycles/tile.
File List
| File | Role |
|---|---|
tile_cache |
New — direct-mapped SRAM cache with tag/valid/hit/miss |
cache_ctrl |
New — per-operand FSM: LOOKUP → HIT_STREAM or MISS_FILL |
gemm_ctrl_cached |
New — extended sequencer with CACHE_REQ / CACHE_WAIT states |
gemm_cached_wrapper |
New — top-level integration |
gemm_cached_wrapper_tb |
New — testbench with DMA model and T1-T6 test suite |
sram_bank |
Existing (ping-pong layer) |
ping_pong_buf |
Existing (ping-pong layer) |
output_buf |
Existing (ping-pong layer) |
gemm_ctrl |
Existing (ping-pong layer) — not used in cached design |
gemm_wrapper |
Existing (ping-pong layer) — not used in cached design |
gemm, pe, mac, line_buffer |
Existing core — unchanged |
Parameters
| Parameter | Default | Description |
|---|---|---|
M |
3 | PE rows |
N |
3 | PE columns |
K |
3 | Dot-product depth |
NUM_TILES |
4 | Tiles per start pulse |
K_PARTS |
1 | K-partitions per tile (for large K) |
SRAM_DEPTH |
8 | Words per ping-pong bank |
CACHE_SETS |
4 | Cache lines per operand |
TAG_WIDTH |
8 | Tag bits (supports 128 distinct A tiles + 128 B tiles) |
DMA Interface
The DMA interface is the only external connection in the cached design. No operand data enters via the wrapper ports — only DMA fills on misses.
dma_X_req ← asserted by RTL when a miss is detected
dma_X_tile_id ← which tile to fetch (same as the tag that missed)
dma_X_ack → host asserts when data is ready to flow (after DRAM latency)
dma_X_we → host drives 1 for each valid data word
dma_X_addr → word index within tile (0..K-1)
dma_X_data → data word (K=3 words, one per clock)
dma_X_done → host pulses on the last word to commit the cache line
The host (or memory controller) sees req and must respond within any number of cycles —
the RTL will stall in CACHE_WAIT indefinitely. Once ack fires, the host must send
exactly K words on consecutive cycles with we=1, then pulse done.
Compile and Run
iverilog -o sim_cached sram_bank.v ping_pong_buf.v output_buf.v tile_cache.v cache_ctrl.v gemm_ctrl_cached.v gemm_cached_wrapper.v line_buffer.v mac.v pe.v gemm.v gemm_cached_wrapper_tb.v && vvp sim_cached
Expected: 54 PASS / 0 FAIL
Test Coverage
| Test | What it proves |
|---|---|
| T1 | Cold miss — DMA fills, miss counter increments, correct result |
| T2 | True hit — no rst between T1 and T2, valid_r intact, hit counter increments, latency 22 < cold 26 |
| T3 pass-1 | 4-tile cold fill — 4 misses, correct C for each unique tag |
| T3 pass-2 | 4-tile warm replay — 4 hits, 83 cycles vs cold 99, same correct C |
| T4 pass-1/2 | Capacity fill + full hit — All 4 A hits confirmed CACHE WORKING |
| T4 note | Eviction arithmetic — tag=4 aliases set=0, would evict tag=0 |
| T5 cold | DMA stall — latency breakdown: 3+3+7+13=26 cycles |
| T5 hit | Hit latency — 22 cycles, saved 4 vs cold |
| T6a | 8 passes × 4 tiles — 28/32 hits = 87.5% as predicted by (N-1)/N formula |
| T6b | 16 passes warm — 64/64 hits = 100% (cache stays warm from T6a) |
| T6c | Cold-start 16 passes — 60/64 = 93.75%, exactly 4 cold misses on pass-0 |