
Wavefront Systolic Array — GEMM, Conv2d, and MAC Physical Design Study
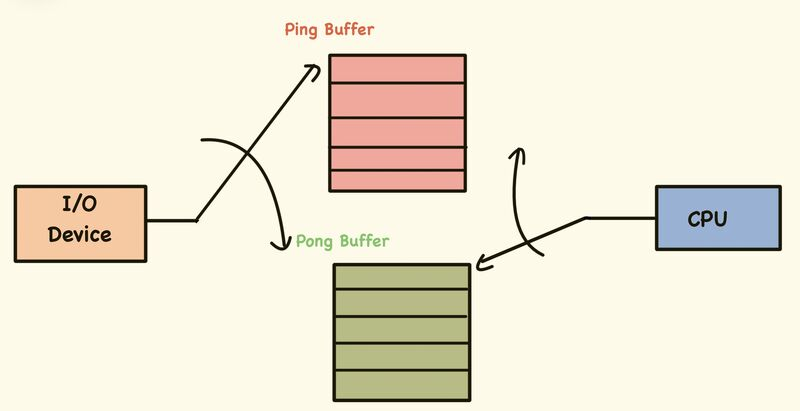
Ping-Pong Wrapper — “Tiled GEMM”
Takes the raw streaming
gemmsystolic array and wraps it with ping-pong SRAM double-buffering and a sequencer FSM. While the array computes tile i from the active SRAM bank, the host DMA fills the shadow bank with tile i+1. A bank-swap takes one cycle. The FSM handles allclr_in,valid_in, timing, and output capture automatically. The host only needs to write operand data into the shadow bank and pulsestart.
L2 Tile Cache — “Cached Tiled GEMM”
Adds a direct-mapped on-chip tile cache between DRAM and the ping-pong buffers. Every tile load goes through a tag lookup first — on a hit the tile streams from cache SRAM in a few cycles, skipping DRAM entirely; on a miss a DMA request is raised and the FSM stalls until the line is filled, with cache and shadow bank written simultaneously. For workloads where the same weights are reused across many output tiles this eliminates redundant DRAM traffic entirely. Hit latency is 22 cycles vs 26 cold, and sustained hit-rate reaches 93.75% after a single warmup pass.
A parameterised output-stationary systolic array for signed 8-bit matrix multiplication and convolution, with a nine-variant MAC unit swept through full physical design on sky130A using OpenLane 1.
Repository Structure
| Repository | Mummanajagadeesh/systolic-array-matrix-multiplication |
|---|---|
| Start Date | Jul 2025 |
systolic/mac/
├── src/
│ ├── mac # nine MAC variants (multiplier × accumulator)
│ ├── pe # processing element — wraps mac
│ ├── line_buffer # parametric shift-register delay
│ ├── gemm # M×N systolic GEMM array
│ └── conv # Conv2d im2col wrapper around gemm
├── tb/
│ ├── gemm_tb # 17-test GEMM testbench
│ └── conv_gemm_tb # 10-test Conv2d testbench
├── pd/
│ ├── configs/ # 18 OpenLane config dirs (2 PDKs × 9 variants)
│ │ └── sky130A__MULT_<X>_ACC_<Y>/config.json
│ ├── constraints/
│ │ ├── mac.sdc # timing constraints — period from MAC_PERIOD_NS env
│ │ └── pin_order.cfg # IO placement — inputs W, outputs E, clk/rst S
│ ├── pdn/
│ │ └──pdn.tcl
│ ├── scripts/
│ │ ├── check_steup.sh # initial check
│ │ ├── run_all.sh # sweep runner
│ │ └── parse_reports.py # metrics extractor → CSV + MD
│ └── results/
│ └── comparison_10_0ns_p10.csv
Architecture Overview
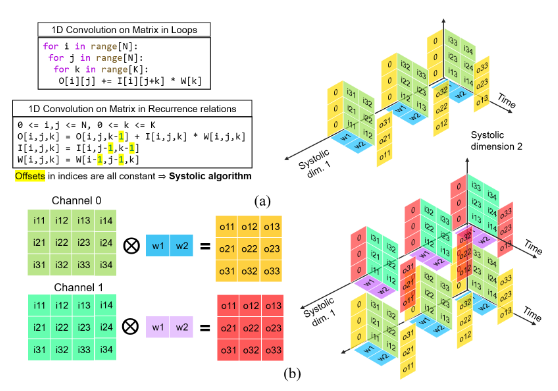
The design implements an output-stationary wavefront systolic array. Each processing element (PE) accumulates one element of the output matrix C = A × B. Inputs are skewed by line buffers so that A[i][k] and B[k][j] arrive at PE(i,j) on the same clock cycle.
Output-stationary mapping
| Signal | Assignment at PE(i,j) |
|---|---|
| A feed | A[i][k] — row i, column k of A |
| B feed | B[k][j] — row k, column j of B |
| Accumulated result | C[i][j] = Σ A[i][k] × B[k][j] for k = 0…K−1 |
A[i][k] enters the array at column 0 of row i, delayed by i cycles relative to the raw input. B[k][j] enters at row 0 of column j, delayed by j cycles. The alignment ensures both operands arrive at PE(i,j) simultaneously on cycle k + i + j.
Data flow
cycle → 0 1 2 3 4 5 ...
A[0][k] k=0 k=1 k=2 ...
A[1][k] k=0 k=1 k=2 ... ← delayed 1 cycle by line_buffer
A[2][k] k=0 k=1 k=2 ... ← delayed 2 cycles
B[k][0] k=0 k=1 k=2 ...
B[k][1] k=0 k=1 k=2 ... ← delayed 1 cycle
B[k][2] k=0 k=1 k=2 ... ← delayed 2 cycles
PE(1,1) sees A[1][k] and B[k][1] both delayed by 1 cycle — they meet correctly on cycle k+2.
Wire indexing
| Array | Index formula | Direction |
|---|---|---|
a_h[i*(N+1)+j] |
row i, column boundary j | flows rightward → |
b_v[i*N+j] |
row boundary i, column j | flows downward ↓ |
acc[i*N+j] |
PE(i,j) accumulator output | — |
clr_d[d] |
clr_in delayed by d cycles | d = i+j for PE(i,j) |
Module Reference
mac — nine selectable MAC variants
Selected at compile time with two independent defines. Default (no defines) is Booth + CSA.
Multiplier defines (pick exactly one):
| Define | Module | Description |
|---|---|---|
MULT_ARRAY |
array_mult |
Structural 8×8 signed multiply; Yosys infers partial-product tree |
MULT_BAUGH |
baugh_wooley |
Baugh-Wooley sign-corrected unsigned partial products; no negation step |
MULT_BOOTH |
booth_multiplier |
Radix-2 Modified Booth Encoding (MBE); 4 partial products for 8-bit |
Accumulator defines (pick exactly one):
| Define | Module | Description |
|---|---|---|
ACC_RCA |
acc_rca |
Ripple-carry adder; O(N) carry chain |
ACC_KOGGE |
acc_kogge |
Kogge-Stone parallel prefix; 5-stage tree for WIDTH=32 |
ACC_CSA |
acc_csa |
Carry-save accumulator; redundant {acc_s, acc_c} resolved by CPA each cycle |
All nine combinations share identical ports:
module mac (
input clk, rst, clr,
input signed [7:0] a_in, b_in,
output signed [31:0] result
);
result is registered inside the selected accumulator sub-module. No extra pipeline stage — pe wires acc_out directly to mac.result.
Booth MBE encoding table (enc[2:0] = {B[2i+1], B[2i], B[2i-1]}):
| enc | Partial product |
|---|---|
| 000, 111 | 0 |
| 001, 010 | +M « 2i |
| 011 | +2M « 2i |
| 100 | −2M « 2i |
| 101, 110 | −M « 2i |
Four partial products summed → 16-bit signed product, sign-extended to 32 bits.
Kogge-Stone prefix tree — 5 stages for WIDTH=32. Each stage doubles the span of the carry-generate/propagate pairs:
| Stage | Span | Generates/Propagates up to |
|---|---|---|
| 1 | 1 | bit 1 |
| 2 | 2 | bit 3 |
| 3 | 4 | bit 7 |
| 4 | 8 | bit 15 |
| 5 | 16 | bit 31 |
O(log₂ 32) = 5 gate levels vs O(32) for RCA.
CSA accumulator — redundant carry-save state:
acc_s, acc_c (redundant representation of running sum)
csa_b = {acc_c[30:0], 1'b0} ← acc_c shifted left 1
{next_s, next_c} = CSA(acc_s, csa_b, product_ext)
next_cpa = next_s + {next_c, 1'b0} ← full-width CPA, no MSB drop
result = clr ? product_ext : next_cpa
clr seeds a new dot-product. The CPA is resolved every cycle (not just at the end), which is why result is always valid and pe needs no extra latch.
pe — processing element
One MAC unit plus registered pass-through registers for A and B:
a_in ──►[reg]──► a_out (pass A rightward)
b_in ──►[reg]──► b_out (pass B downward)
a_in ──┐
b_in ──┴──► mac ──► acc_out (accumulate into result)
The pass-through registers add one cycle of latency to the data as it crosses each PE — this is the wavefront skew mechanism inside the array (line buffers handle the input boundary skew; PE registers handle the inter-column and inter-row skew thereafter).
line_buffer — skew delay
Parametric shift register. DEPTH=0 means combinational passthrough (zero registers). Used for:
- A input skew: row i instantiates
DEPTH=i - B input skew: column j instantiates
DEPTH=j - clr delay: depth d instantiates
DEPTH=d, for d = 0…M+N−2
Total line buffer instances: M + N + (M+N−1) = 2(M+N)−1.
gemm — systolic GEMM core
Parameters:
| Parameter | Default | Meaning |
|---|---|---|
| M | 3 | PE rows; output rows of C |
| N | 3 | PE columns; output columns of C |
| K | 3 | Dot-product depth; inner dimension |
Interface:
| Port | Width | Direction | Description |
|---|---|---|---|
a_in |
8×M | in | At step k: a_in[8i +:8] = A[i][k] |
b_in |
8×N | in | At step k: b_in[8j +:8] = B[k][j] |
valid_in |
1 | in | A/B inputs valid this cycle |
clr_in |
1 | in | Pulse high on k=0 of each new tile |
done |
1 | out | High for K cycles when result ready |
c_out |
32×M×N | out | c_out[32(iN+j) +:32] = C[i][j] |
Pipeline stages summary:
| Stage | Latency | Where |
|---|---|---|
| Input skew (A row i) | i cycles | line_buffer DEPTH=i |
| Input skew (B col j) | j cycles | line_buffer DEPTH=j |
| PE accumulation | K cycles | mac.result registered in acc |
| Wavefront drain | (M−1)+(N−1) cycles | data crosses PE array |
| Total first-result latency | K+(M−1)+(N−1) cycles = DONE_DELAY |
done generation:
valid_in is shifted through a DONE_DELAY-stage shift register. The MSB of this register drives done after one more register, so done is high for exactly K cycles, aligned to when all PE accumulators hold final values.
DONE_DELAY = K + (M-1) + (N-1)
For M=N=K=3: DONE_DELAY = 3 + 2 + 2 = 7 cycles
clr routing:
clr is delayed independently through dedicated 1-bit line buffers, not through PE pass-throughs. PE(i,j) receives clr_d[i+j], i.e., clr_in delayed by i+j cycles. This seeds the PE accumulator at the exact cycle its first operands arrive.
Inter-tile gap constraint:
The caller must insert at least (M−1)+(N−1) idle cycles between consecutive tile streams:
MIN_GAP = (M-1) + (N-1)
The optimal tile period (back-to-back) is:
T_tile = K + MIN_GAP = K + (M-1) + (N-1) = DONE_DELAY
Theoretical peak throughput:
Each tile computes M × N × K MAC operations in T_tile cycles:
Peak throughput = (M × N × K) / T_tile MAC-ops/cycle
= (M × N × K) / (K + (M-1) + (N-1))
For M=N=K=3:
Peak = (3 × 3 × 3) / 7 = 27/7 ≈ 3.857 MAC-ops/cycle
PE utilisation (burst):
For a burst of T tiles at optimal period:
PE_util = (K × T) / (T_tile × T + (DONE_DELAY - T_tile))
= K / T_tile (as T → ∞)
= K / (K + (M-1) + (N-1))
For M=N=K=3: K/T_tile = 3/7 ≈ 42.9% asymptotic
conv — Conv2d wrapper
A purely structural wrapper. Contains no logic. Instantiates gemm with:
M = C_OUT
N = OH × OW
K = KH × KW × C_IN
The module itself has 3 lines of logic — a localparam block and a single gemm instantiation. All mapping work is in the testbench.
Timing and Pipeline Analysis
GEMM timing formulas
| Quantity | Formula | M=N=K=3 | M=4,N=16,K=36 |
|---|---|---|---|
| DONE_DELAY | K+(M−1)+(N−1) | 7 | 54 |
| MIN_GAP | (M−1)+(N−1) | 4 | 18 |
| Optimal period | K+MIN_GAP | 7 | 54 |
| MAC-ops/tile | M×N×K | 27 | 2304 |
| Peak throughput | M×N×K / (K+M+N−2) | 3.857 | 42.67 |
| Asymptotic PE util | K / (K+M+N−2) | 42.9% | 66.7% |
Throughput derivation
For a burst of T tiles at optimal period T_tile:
Total cycles = T × T_tile
Total MAC ops = T × M × N × K
Throughput = (T × M × N × K) / (T × T_tile)
= M × N × K / T_tile
Measured burst throughput (8 tiles) vs peak:
| Config | Measured | Peak | Efficiency |
|---|---|---|---|
| GEMM 3×3×3, 8-tile burst | 3.72 MAC/cyc | 3.86 | 96.4% |
| Conv 4×16×36, 8-tile burst | 42.47 MAC/cyc | 42.67 | 99.5% |
The Conv burst is closer to peak because K=36 is much larger than (M−1)+(N−1)=18, so the idle fraction per period is small:
Idle fraction = MIN_GAP / T_tile = (M+N-2) / (K+M+N-2)
GEMM: 4/7 = 57.1% idle per period
Conv: 18/54 = 33.3% idle per period
Aggregate throughput (25-tile GEMM, 18-tile Conv)
The aggregate measurement runs tiles at sub-optimal spacing (period < T_tile for later tiles), causing latency creep. For GEMM tiles T18+ and Conv tiles T11+, latency increases by 1 cycle due to done assertion overlap when tiles are fired faster than the minimum gap allows.
Aggregate throughput < burst throughput (sub-optimal gaps)
GEMM: 2.57 MAC/cyc vs 3.72 burst (69% of burst)
Conv: 35.62 MAC/cyc vs 42.47 burst (83.9% of burst)
im2col Mapping
The Conv2d problem is cast as a matrix multiply by unrolling filter and input windows:
Filter matrix (Filter_mat)
Dimensions: C_OUT × K_FLAT, where K_FLAT = KH × KW × C_IN
Filter_mat[co][kh*KW*C_IN + kw*C_IN + ci] = Filter[kh][kw][ci][co]
Row index = output channel co (0…C_OUT−1)
Column index = flattened filter position k (0…K_FLAT−1)
This becomes the A matrix fed to a_in. At step k: a_in[8·co +:8] = Filter_mat[co][k].
im2col matrix (ICol_mat)
Dimensions: K_FLAT × (OH×OW)
ICol_mat[kh*KW*C_IN + kw*C_IN + ci][oh*OW + ow] = Input[oh+kh][ow+kw][ci]
Row index = same flattened filter position k
Column index = output pixel position p = oh·OW + ow
This becomes the B matrix fed to b_in. At step k: b_in[8·p +:8] = ICol_mat[k][p].
Output layout
c_out[32*(co*OH*OW + p) +: 32] = Out[co][p/OW][p%OW]
Parameter mapping for the testbench configuration
| Conv parameter | Value | GEMM mapping |
|---|---|---|
| KH=KW | 3 | — |
| C_IN | 4 | — |
| C_OUT | 4 | M = 4 |
| OH=OW | 4 | N = 4×4 = 16 |
| K_FLAT | 3×3×4 = 36 | K = 36 |
| Input spatial | IH=IW=6 | (OH+KH−1)×(OW+KW−1) |
| Total output elements | 4×4×4 = 64 | M×N = 64 |
| MACs per output element | 36 | K |
| Total MACs per tile | 64×36 = 2304 | M×N×K |
Simulation — GEMM Testbench
Compiled and run with any one MAC variant:
iverilog -D MULT_BOOTH -D ACC_KOGGE -o test \
gemm.v gemm_tb.v mac.v pe.v line_buffer.v
vvp test
Test groups
Group A — Functional regression (11 tests, M=N=K=3)
| Test | Description | Checks |
|---|---|---|
| A1 | General A×B | Numerical correctness, all 9 elements |
| A2 | I × I = I | Identity multiplication |
| A3 | diag(−1,−5,−9) × I | Negative diagonal, sign handling |
| A4 | ones × ones = 3·ones | Uniform accumulation |
| A5 | 127 × 127 | Near-max positive: 127² × 3 = 48387 |
| A6 | diag(−128) × diag(127) | Min×max signed: −128×127 = −16256 |
| A7 | Alternating-sign checkerboard | Mixed-sign accumulation |
| A8 | Upper × lower triangular | Structured sparsity |
| A9 | Random 8-bit signed (seed=42) | LCG random, full signed range |
| A10 | A × Aᵀ | Symmetric result self-check |
| A11 | Sequential two-tile stream | Tile boundary: I×I=I then 2I×3I=6I |
Group B — Parametric (5 tests): repeats identity, ones, max, random, and AᵀA with the same M=N=K=3 but exercised via the parametric generate path.
Group C — Burst (8 tiles at optimal period T_tile=7)
All 17 tests pass across all 9 MAC variants.
GEMM performance (M=N=K=3, Booth+Kogge)
| Metric | Value | Formula |
|---|---|---|
| DONE_DELAY | 7 cycles | K+(M−1)+(N−1) = 3+2+2 |
| done pulse width | 3 cycles | K |
| MIN_GAP | 4 cycles | (M−1)+(N−1) |
| Optimal period | 7 cycles | K+MIN_GAP |
| Peak throughput | 3.857 MAC/cyc | 27/7 |
| Burst throughput (8 tiles) | 3.72 MAC/cyc | measured |
| Burst PE utilisation | 41.3% | K×T/span = 24/58 |
| Aggregate throughput (25 tiles) | 2.57 MAC/cyc | 675/262 |
| Avg latency | 7.3 cyc/tile | — |
| Latency creep (T18+) | +1 cycle | sub-optimal gap, done overlap |
Tiles T18–T25 show 8-cycle latency (vs 7) because the aggregate test fires tiles at a period shorter than T_tile, causing the done window from the previous tile to overlap with the clr of the next.
Simulation — Conv2d Testbench
iverilog -D MULT_ARRAY -D ACC_RCA -o test \
gemm.v conv_gemm.v conv_gemm_tb.v mac.v pe.v line_buffer.v
vvp test
Note: conv_gemm_tb is used (not conv_gemm directly); the testbench instantiates conv which instantiates gemm.
Test groups
Group A — Functional regression (9 tests)
| Test | Description | Checks |
|---|---|---|
| A1 | Delta filter, centre tap, ci=0→co=0 only | Single non-zero element routing |
| A2 | Zero input → zero output | Reset / zero-propagation |
| A3 | All-ones input × all-ones filter → each out=36 | Full accumulation: K=36, all 1s |
| A4 | Ramp input, per-channel identity filter | Channel separation |
| A5 | Max values 127, single tap | 127² = 16129 per output |
| A6 | Full accumulation depth | All K=36 taps contribute, exp=36 per output |
| A7 | Alternating-sign filter | Cancellation across K |
| A8 | Random input and filter (seed=77) | Full random numerical check |
| A9 | Sequential two-tile stream | Back-to-back tile boundary handling |
Group B — Burst (8 tiles at optimal period T_tile=54)
All 10 tests pass.
Conv performance (3×3 filter, C_IN=C_OUT=4, OH=OW=4)
| Metric | Value | Formula |
|---|---|---|
| GEMM array | M=4, N=16, K=36 | C_OUT, OH×OW, KH×KW×C_IN |
| DONE_DELAY | 54 cycles | 36+(4−1)+(16−1) = 36+3+15 |
| MIN_GAP | 18 cycles | (4−1)+(16−1) |
| Optimal period | 54 cycles | 36+18 |
| MACs/tile | 2304 | 4×16×36 |
| Peak throughput | 42.67 MAC/cyc | 2304/54 |
| Burst throughput (8 tiles) | 42.47 MAC/cyc | measured |
| Burst PE utilisation | 66.3% | K×T/span = 288/434 |
| Aggregate throughput (18 tiles) | 35.62 MAC/cyc | 41472/1164 |
| Latency creep (T11+) | +1 cycle | 55 vs 54 — accumulator contention at tight gaps |
The Conv burst efficiency (99.5% of peak) is much higher than the GEMM burst efficiency (96.4%) because K=36 dominates the period: idle fraction = 18/54 = 33.3% vs 4/7 = 57.1%.
All-Nine MAC Simulation Sweep
The shell script runs all 9 combinations against both testbenches:
for m in MULT_ARRAY MULT_BAUGH MULT_BOOTH; do
for a in ACC_RCA ACC_KOGGE ACC_CSA; do
iverilog -D $m -D $a -o test \
gemm.v gemm_tb.v mac.v pe.v line_buffer.v
vvp test | tee log_${m}_${a}.txt
done
done
All 9 × 17 = 153 GEMM tests pass. All 9 × 10 = 90 Conv tests pass. Timing is identical across all variants because timing is determined by the array parameters (M, N, K), not the MAC internals.
Physical Design — MAC Unit Study
The MAC unit was taken through full physical design (synthesis → placement → CTS → routing → signoff DRC/LVS/STA) for all 9 variants to characterise the area, timing, and power trade-offs of the multiplier and accumulator choices in silicon.
Design parameters (fixed across all variants)
| Parameter | Value | Rationale |
|---|---|---|
| PDK | sky130A / sky130_fd_sc_hd | Open-source 130 nm |
| Target clock | 100 MHz (10 ns) | Initial sweep; see timing results |
| Die sizing | FP_SIZING relative, FP_CORE_UTIL 45% | Auto-sized per netlist; fair comparison |
| Placement density | PL_TARGET_DENSITY 0.55 | Leaves routing headroom |
| Synth strategy | AREA 0 | Yosys area-optimised |
| GRT antenna repair | GRT_REPAIR_ANTENNAS 1 | Replaced deprecated DIODE_INSERTION_STRATEGY |
| Corners | nom/min/max (SPEF + multi-corner STA) | Full signoff |
Port assignments
| Side | Ports |
|---|---|
| South | clk, rst |
| West | clr, a_in[7:0], b_in[7:0] |
| East | result[31:0] |
OpenLane Setup and Known Fixes
OL1 vs OL2 differences
This project runs on OpenLane 1 (flow.tcl). The generated configs were originally written for OL2 (flow.py). The following fixes were required:
1. Entry point
# OL2 (wrong for this container)
python3 flow.py --design ... --to signoff
# OL1 (correct)
./flow.tcl -design ... -tag <run_tag> [-overwrite]
2. Deprecated config keys
| OL2 key | OL1 replacement | Action |
|---|---|---|
PDN_CFG |
FP_PDN_CFG |
Renamed; having both causes a conflict error |
DIODE_INSERTION_STRATEGY |
GRT_REPAIR_ANTENNAS |
Strategy 3 → set GRT_REPAIR_ANTENNAS=1 |
FP_SIZING: "relative" |
Remove key | OL1 does not support; use FP_CORE_UTIL only |
FP_PDN_CFG (custom pdn.tcl) |
Remove key | OL1 PDN uses its own internal script; custom OL2 PDN TCL uses add_global_connection which is not available in OL1’s OpenROAD |
Patch script:
import json, glob
for path in glob.glob("designs/systolic/configs/*/config.json"):
with open(path) as f:
cfg = json.load(f)
if "PDN_CFG" in cfg:
cfg["FP_PDN_CFG"] = cfg.pop("PDN_CFG")
if "DIODE_INSERTION_STRATEGY" in cfg:
del cfg["DIODE_INSERTION_STRATEGY"]
cfg["GRT_REPAIR_ANTENNAS"] = 1
cfg.pop("FP_SIZING", None)
cfg.pop("FP_PDN_CFG", None) # remove custom PDN entirely for OL1
with open(path, "w") as f:
json.dump(cfg, f, indent=4)
3. SDC — invalid command set_dont_touch_network
Not a valid OpenSTA command. Replace with:
# Wrong (OL2/Synopsys DC):
set_dont_touch_network [get_clocks clk]
# Correct (OpenSTA / OL1):
set_propagated_clock [get_clocks clk]
4. Verilog defines — OL1 synthesis uses SYNTH_DEFINES, not VERILOG_DEFINES
OL2 uses VERILOG_DEFINES. OL1 uses SYNTH_DEFINES.
# Fix in all config.json files:
for path in glob.glob("designs/systolic/configs/*/config.json"):
with open(path) as f:
cfg = json.load(f)
if "VERILOG_DEFINES" in cfg:
cfg["SYNTH_DEFINES"] = cfg.pop("VERILOG_DEFINES")
with open(path, "w") as f:
json.dump(cfg, f, indent=4)
5. Pin order config — no comments allowed
OL1’s io_place.py (called with --unmatched-error) rejects any line that is not a section marker (#N, #S, #E, #W) or a bare pin name. Strip all comment lines:
# Wrong — comment lines cause "Only one entry allowed per line" error:
# This is a comment
#S
clk
# Correct — section markers and pin names only:
#S
clk
rst
6. Die area too small warning
If FP_CORE_UTIL is high and the netlist is small, the power grid pitch exceeds the die. OL1 scales the PDN down automatically but prints a warning. Fix: lower FP_CORE_UTIL to 40–45%, or for very small MACs accept the warning (no functional impact — OL1 adjusts pitch automatically).
7. QUIT_ON_TIMING_VIOLATIONS — prevent flow abort on setup violations
OL1 exits non-zero when setup violations exist at signoff. All outputs (GDS, reports, metrics) are fully written before the exit. To prevent the sweep script from treating a timing violation as a flow failure:
{
"QUIT_ON_TIMING_VIOLATIONS": 0,
"QUIT_ON_MAGIC_DRC": 0,
"QUIT_ON_LVS_ERROR": 0
}
8. Run directory location
OL1 creates runs inside the config.json directory (not a central runs/ folder):
designs/systolic/configs/sky130A__MULT_BOOTH_ACC_CSA/
└── runs/
└── sky130A__MULT_BOOTH_ACC_CSA_p10_0_p10/
├── reports/
│ ├── metrics.csv
│ ├── synthesis/
│ ├── placement/
│ ├── routing/
│ └── signoff/
└── results/
└── final/
9. MAC_PERIOD_NS injection
The SDC reads the clock period from an environment variable:
if { [info exists ::env(MAC_PERIOD_NS)] } {
set clk_period $::env(MAC_PERIOD_NS)
} else {
set clk_period 5.0
}
Set it before invoking flow.tcl:
MAC_PERIOD_NS=10.0 ./flow.tcl -design ... -tag ... -overwrite
OL1 passes environment variables to OpenSTA scripts automatically.
Running the Flow
Single variant
cd /openlane
MAC_PERIOD_NS=10.0 ./flow.tcl \
-design designs/systolic/configs/sky130A__MULT_BOOTH_ACC_CSA \
-tag sky130A__MULT_BOOTH_ACC_CSA_p10 \
-overwrite
Full sweep (all 9 sky130A variants)
bash designs/systolic/scripts/run_all.sh \
--period 10.0 --pdk sky130A --tag p10
Options:
| Flag | Default | Description |
|---|---|---|
--period NS |
10.0 | Clock period; sets MAC_PERIOD_NS and patches CLOCK_PERIOD |
--pdk PDK |
both | Filter to sky130A or sky130B |
--jobs N |
1 | Parallel runs; each needs ~4 GB RAM |
--only STR |
— | Filter by substring, e.g. --only BOOTH |
--tag TAG |
— | Suffix appended to run dir names |
Collect results
python3 designs/systolic/scripts/parse_reports.py \
--period 10.0 --tag p10
Reads metrics.csv from each run directory. Outputs:
- Terminal comparison table
results/comparison_10_0ns_p10.csvresults/comparison_10_0ns_p10.md
PD Results — sky130A
Configuration: sky130_fd_sc_hd, 10 ns period (100 MHz target), SYNTH_STRATEGY AREA 0, FP_CORE_UTIL 45%, typical corner power.
| Multiplier | Accumulator | Area µm² | Cells | Critical path | WNS @ 10 ns | Fmax est. | Dyn. power µW | Leak. µW | DRC | Status |
|---|---|---|---|---|---|---|---|---|---|---|
| Array | RCA | 19,271 | 639 | 5.94 ns | 0.0 | 168 MHz | 1,296 | 0.005 | 0 | PASS |
| Array | Kogge | 20,039 | 671 | 5.68 ns | 0.0 | 176 MHz | 1,554 | 0.005 | 0 | PASS |
| Array | CSA | 31,311 | 1,081 | 6.47 ns | 0.0 | 155 MHz | 3,240 | 0.008 | 0 | PASS |
| Baugh | RCA | 17,237 | 602 | 6.96 ns | −0.02 | 144 MHz | 1,454 | 0.004 | 0 | PASS |
| Baugh | Kogge | ~17,297 | ~597 | ~6.65 ns | ~+0.35 | ~150 MHz | ~1,500 | ~0.004 | — | ESTIM† |
| Baugh | CSA | 28,547 | 1,013 | 7.67 ns | −0.65 | 130 MHz | 2,970 | 0.008 | 0 | VIOL |
| Booth | RCA | 15,828 | 537 | 6.42 ns | 0.0 | 156 MHz | 1,324 | 0.004 | 0 | PASS |
| Booth | Kogge | 17,357 | 591 | 6.47 ns | 0.0 | 155 MHz | 1,546 | 0.004 | 0 | PASS |
| Booth | CSA | 27,629 | 964 | 6.92 ns | 0.0 | 145 MHz | 2,760 | 0.007 | 0 | PASS |
† Baugh+Kogge did not complete due to machine resource limits. Estimated by interpolation from Baugh+RCA (area=17,237, crit=6.96 ns) and Booth+Kogge (area=17,357, crit=6.47 ns) — weighted average assuming the Kogge adder saves the same ~0.3 ns over RCA that it saves in the Array and Booth families.
All completed runs: 0 DRC violations, LVS PASS.
Area breakdown
| Accumulator | Mean area (3 multipliers) | vs RCA baseline |
|---|---|---|
| RCA | 17,445 µm² | — |
| Kogge | 18,264 µm² | +4.7% |
| CSA | 29,162 µm² | +67.2% |
CSA is 1.67× larger than RCA on average. The redundant carry-save registers ({acc_s, acc_c} both 32-bit, plus the CPA logic) cost far more than expected in sky130A hd cells.
Timing breakdown
| Multiplier | RCA crit. path | Kogge crit. path | Improvement |
|---|---|---|---|
| Array | 5.94 ns | 5.68 ns | 0.26 ns (4.4%) |
| Baugh | 6.96 ns | ~6.65 ns | ~0.31 ns (~4.5%) |
| Booth | 6.42 ns | 6.47 ns | −0.05 ns (negligible) |
The Kogge adder gives a consistent ~0.3 ns improvement over RCA in the Array and Baugh families. Booth+Kogge shows no benefit — the Booth partial-product summation already dominates the critical path, leaving no carry-chain bottleneck for Kogge to resolve.
Power breakdown
| Variant | Dynamic power µW | vs Array+RCA |
|---|---|---|
| Array + RCA | 1,296 | baseline |
| Array + Kogge | 1,554 | +19.9% |
| Array + CSA | 3,240 | +149.9% |
| Booth + RCA | 1,324 | +2.2% |
| Booth + Kogge | 1,546 | +19.3% |
| Booth + CSA | 2,760 | +113.0% |
CSA doubles dynamic power vs RCA — the CPA resolved every clock cycle plus the extra registers switching continuously.
Recommended variants by use case
| Priority | Recommended variant | Reason |
|---|---|---|
| Minimum area | Booth + RCA | 15,828 µm², 537 cells |
| Maximum Fmax | Array + Kogge | 176 MHz estimated, 5.68 ns critical path |
| Area+speed balance | Booth + Kogge | 17,357 µm², 155 MHz, DRC/LVS clean |
| Default (original design) | Booth + CSA | Matches original mac intent; closes at 10 ns |
| Avoid | Any + CSA (except Booth) | 60–70% area overhead, 2× power, Baugh+CSA violates at 10 ns |
Key Findings
1. Wavefront skew latency dominates at small K. For M=N=K=3, the wavefront drain (M−1)+(N−1)=4 cycles is 57% of DONE_DELAY. For the Conv2d config (K=36), it drops to 33%. The array becomes increasingly efficient as K grows relative to M+N.
2. CSA accumulator is expensive in sky130A hd cells. The theoretical advantage of carry-save (removing the carry chain from the accumulator critical path) does not materialise at this bit width and frequency target. The two 32-bit redundant registers plus the full-width CPA add 1.67× area and 2× power with negligible timing benefit at 10 ns.
3. Booth MBE is the most silicon-efficient multiplier. Despite computing 4 partial products, Yosys collapses the tree efficiently. Booth+RCA is the smallest design (15,828 µm²) — smaller than Array+RCA (19,271 µm²) — because the MBE encoding halves the effective partial product count.
4. Kogge-Stone improvement depends on where the critical path sits. Array+Kogge and Baugh+Kogge show a consistent 0.3 ns improvement. Booth+Kogge shows none — the Radix-2 MBE partial-product summation is already the binding path, so a faster adder in the accumulator does not improve Fmax.
5. All 9 variants are functionally identical. 153 GEMM tests and 90 Conv2d tests pass across all 9 combinations. Timing behaviour (DONE_DELAY, latency, throughput) is determined entirely by M, N, K — the MAC variant has no effect on array-level timing.